http://invisible-island.net/ncurses/
Copyright © 2011–2021,2022 by Thomas E. Dickey
tctest is a tool which helps analyze termcap implementations, i.e., the runtime library. It uses the termcap runtime library to retrieve terminal descriptions, which it reports in a standard format. The termcap library may alter or lose information from the original textual terminal descriptions. To understand what tctest is reporting, you need more information than is provided by other sources of information.
Outside of manual pages, the O'Reilly book termcap & terminfo by Strang et al (1986) is the usual reference for this material. However, it does not present differences among implementations, and covers only the very beginning of the story. I have provided more information.
Termcap evolved in stages:
While termcap is said to have been created in 1978, the oldest sources that are still available are part of the BSD releases beginning a year later (with 3BSD, files dated November 1979 to January 1980). This, and several later releases, can be downloaded from the Unix Archive.
The initial release of the termcap library uses syntax which
would (mostly) work with current implementations. The
tgoto function was later revised for these
changes:
%<xy by
"%>xy%B and %D%. function, adding a
workaround for newlines versus tabs%n and
%rThe 3BSD tarball includes manpages termlib.3
(termcap library) and termcap.5 (termcap format), which describes
most of the syntax.
This is the reference version for termcap syntax (noting that
features such as the TERMCAP environment variable
are not syntax, but configurability).
Terminal data is read from a text file (or from the
TERMCAP environment variable) using the
tgetent function. It has two parameters:
Loading the terminal data is subject to both the parameters and environment variables:
TERMCAP variable is set, and nonempty
TERMCAP variable begins with a
“/”, then that is used as the filename from
which to read terminal descriptions.TERM variable is set,
and if it matches the name
parameter then the content of the TERMCAP
variable is used.TERMCAP variable is not set to a
nonempty string then the default termcap text file
(/etc/termcap) is used.TERMCAP variable could not be opened, then the
default termcap text file is used.One interesting quirk of the termcap library
is that tgetent can be called recursively to include
a parent description marked at the end of any description. On
each recursion, the name parameter is set to the
parent's name, which in turn is matched against
TERM. In this way, the TERMCAP variable
could be used (instead of providing the entry to match the
caller's given name) to override any single entry in
the chain of recursion.
The basic syntax is as follows:
Each entry begins in the first column.
An entry may have continuation lines, indicated by a “\” at the end of the preceding line.
Continuation lines should begin with whitespace, usually a tab.
One or more names begin the entry. Names are separated by vertical bar “|”.
An optional description follows the last vertical bar and extends to the next colon.
Capabilities (data) are separated by colons “:”.
Each capability has a two-character name which cannot include whitespace or any of the special punctuation (vertical bar “|”, colon “:”, backslash “\\”, caret “^”).
There are three types of capabilities:
Strings can contain special characters, denoted with “\” or “^”.
Strings can contain functions, denoted with “%”.
One string capability, tc is special. Its value is the name of another terminal description which is included (after removing its name and description) at runtime. This must be the last capability in the entry, since there is no provision for inserting into the resulting buffer.
As a special case, if a capability name is followed by by “@”, then the capability is cancelled, which is different from being empty or missing. An empty boolean capability is false, an empty number is -1, and an empty string is a null pointer. The library functions that return values cannot tell which type a cancelled capability “really” is.
The two-character name is matched without requiring a
trailing NUL byte in the caller's parameter. The
comparison by the library stops if it sees a NUL
in the termcap text, which leads to an interesting quirk: a
boolean capability at the end of the buffer will
match a single-character name (without checking if the
caller's parameter has a corresponding NUL.
Numeric and string capabilities do not fall into this special
case because their names must be followed with a value.
The termcap library has these functions for retrieving data and using it:
The termcap entry along with any "tc="
resolution must be no longer than 1023 bytes. After
including a terminal description, the buffer is rechecked
for a trailing "tc=", recurring up to 32
times.
The termcap library checks the 1023-byte limit, but various implementations are buggy and will dump core on too-long entries.
To allow entering special characters, the
termcap library recognizes a limited set of escapes (character
sequences beginning with “\” backslash which are
substituted at runtime in tgetstr:
Source Result \E escape \\ backslash \b backspace \f form-feed \n newline \r return \t tab
The termcap library also recognizes special characters encoded as octal numbers, again using backslash to denote an escape. For example, the ASCII escape character can be represented in a termcap as “\E” or "\033". Oddly, the BSD 4.2 library accepts \8 and \9 (any decimal digit), though the computation assumes the base is 8.
Escaped characters not in the table are passed through as the
character itself. An escaped colon requires special handling to
work around a design defect in the tskip function
that splits up the runtime data returned by tgetstr:
it ignores the backslash character.
There are also control character substitutions using “^”. Those mask (logical AND) the value of the next character to 5 bits, making the result in the range 0-31.
Conventionally, “^” markers use the uppercase alphabetic characters plus the punctuation characters in the same range (of 32) which map to controls by stripping all but the low 5 bits, i.e., “@”, “[”, “\”, “]”, “^” and “_”. For instance, there are 41 occurrences of “^_” in the BSD 4.2 termcap.
One pitfall when comparing termcap and
terminfo is that DEL (127, represented in terminfo
by “^?”) is not treated specially by termcap; it must
be given as "\177". A “^?” seen by a BSD 4.2
termcap library gives the same result as “^_”, i.e.,.
31.
The termcap library handles more than just special characters.
It provides support for cursor-addressing via the
tgoto function. Given two numbers and a string,
tgoto checks for functions (marked with
“%”), and performs those functions using the two
numbers. In the BSD 4.2 tarball, a list of these functions
is found in comments in the source code:
* The following escapes are defined for substituting row/column: * * %d as in printf * %2 like %2d * %3 like %3d * %. gives %c hacking special case characters * %+x like %c but adding x first * * The codes below affect the state but don't use up a value. * * %>xy if value > x add y * %r reverses row/column * %i increments row/column (for one origin indexing) * %% gives % * %B BCD (2 decimal digits encoded in one byte) * %D Delta Data (backwards bcd) * * all other characters are ``self-inserting''.
The comments do not mention “%n”, though it is documented in the BSD 4.2 manpage. Strang did mention it, but made an error, stating that the value is exclusive-OR'd with (octal) 01400. The code uses 0140, a single-byte value, and the operation is performed on both row/column values.
Given an unrecognized “%” function,
tgoto returns "OOPS".
The same functions could be used for other capabilities than
cm (cursor-movement). The BSD 4.2 termcap file
uses tgoto functions for several other capabilities
(shown with their more familiar terminfo names):
Long terminfo name Short name Termcap Description parm_insert_line il AL insert #1 lines (P*) parm_dch dch DC delete #1 characters (P*) parm_delete_line dl DL delete #1 lines (P*) parm_ich ich IC insert #1 characters (P*) parm_left_cursor cub LE move #1 characters to the left (P) parm_right_cursor cuf RI move #1 characters to the right (P*) parm_up_cursor cuu UP up #1 lines (P*) column_address hpa ch horizontal position #1, absolute (P) cursor_address cup cm move to row #1 columns #2 change_scroll_region csr cs change region to line #1 to line #2 (P) row_address vpa cv vertical position #1 absolute (P) to_status_line tsl ts move to status line, column #1
This made no change to the syntax of termcap.
In Tahoe, the section 3 "termcap" manpage (dated September 1987) provided more ways to find the termcap file.
The handling of the TERMCAP
environment variable was modified to take into account a new
TERMPATH environment variable:
TERMCAP
environment variable.TERMCAP, it reverts to opening the
system default termcap file.TERMCAP does not contain a value
beginning with “/”
TERMPATH is set to a nonempty
value, the library saves that as a list to search..termcap as the
first item in a list:
HOME environment variable
is set, it looks for
$HOME/.termcap.termcap
in the current directory.It then appends
/usr/share/misc/termcap to the list.
TERMCAP as a list to search.TERMCAP or TERMPATH
are set, the library will not search the default termcap
database. Therefore, the quirk
mentioned for BSD 4.2 is not possible with the
BSD 4.3 library..termcap in the current
directory is not mentioned.The section 5 "termcap" manpage (dated November 1985) notes
termcap was replaced by terminfo in UNIX System V Release 2.0. The transition will be relatively painless if capabilities flagged as "obsolete" are avoided.
That is, termcap capabilities were from that point derived from terminfo, and those that had no counterpart in terminfo were deemed obsolete.
The manpage listed 179 capabilities, marking 25 obsolete. One
("ma") is still a termcap name, but used for a
different purpose. The others are gone (except as recognized by
ncurses).
Generally, releases of termcap databases increase with time, but the number of obsolete entries did not decrease immediately just because it was documented in the manpage:
Release Entries Total Capabilities Distinct Capabilities Total Obsolete Total Obsolete 3BSD 81 1289 137 99 8 BSD4.2 328 10957 954 140 14 Solaris 10 470 15838 1051 195 17 BSD4.3 539 19404 1224 248 17 BSD4.4 552 20152 1256 268 18 termcap 2.0.8 900 49407 521 352 9 termcap 1.3.1 1274 88103 861 374 13 ncurses 1583 95961 1011 399 13
Considering the size, Solaris 10's termcap is likely based on one of the earlier BSD 4.3 releases, with minor updates. It is not directly related to Solaris' terminfo database, which dates from the mid-1990s.
To improve performance, the developers changed storage from a flat text-file to hashed databases. This was new work done by Casey Leedom, called "getcap". Incidentally, the rewrite got rid of most of the problems from BSD 4.2's buffer limit-checks.
The use of TERMCAP and TERMPATH
environment variables was unchanged from BSD 4.3.
More important for portability, BSD 4.4 termcap supports
multiple "tc=" capabilities in an entry (like
terminfo). Unlike terminfo, this termcap implementation does no
merging of the capabilities. It simply does a depth-first
traversal of the entry, replacing each "tc="
capability with the text from the corresponding entry.
None of the entries in the BSD 4.4 termcap file use this feature, however.
It also extended the syntax of termcap, adding some redundant escapes:
Source Result \B backspace \C colon \F form-feed \N newline \R return \T tab \c colon \e escape
Only one entry in the BSD 4.4 termcap file uses any of
those (two instances of “\L” in tek4113,
which happens to match the BSD 4.3 entry in that
instance).
It also allows numbers to be hexadecimal or octal, using C-style “0x” or “0” prefixes respectively. Likewise, hexadecimal values are unused in the BSD 4.4 termcap.
BSD 4.4 termcap eliminates a quirk of preceding releases.
Octal escapes are different, i.e., cgetstr ignores
“\8” and “\9”, passing through
“8” and “9” respectively.
BSD 4.4 termcap discards a “^” control sequence which is followed by a colon or by the end of the entry.
BSD 4.4 termcap also treats “\:” as the end of a capability, making it consistent with BSD 4.2's termcap library (the design defect noted previously). Six entries in BSD 4.4's termcap file used “\:” as data:
ibm3163, to disable the status line,dg460-ansi for the F9 function key, andwy60, wy60-25,
wy60-42, wy60-43 in variations of the
reset-string.One (f100) used it in the sense that
cgetstr assumed: it was leftover from a stray edit
which deleted a newline, e.g., to save bytes.
Which is correct? That is hard to determine. Neither IBM nor
ncurses show status-line features for the ibm3163
entry. The Wyse-60 entries in ncurses are from a different
source, and do not use the particular initialization string which
was modified. The dg460-ansi entry differs, using
kf9=\E[010z versus BSD 4.4's
kf9=\E[00\:z. That was due to one of Raymond's
changes (likely a guess):
# fixed garbled ":k9=\E[00\:z:" capability -- esr)
VT100.net has a user manual for the terminal, but while the manual promises that the user function keys are documented in Appendix C, the information is not there, either. On the other hand, it has a manual for the 411/461 models which documents “\072” for that key.
Finally, BSD 4.4 extends the way capabilities can be
cancelled. Termcap capability names are not (except for special
cases such as tc) predefined. That opens up the
possibility of having the same name for a boolean capability, as
well as a number and a string. BSD 4.4 takes note of this,
providing a way to cancel just a numeric capability or a string
capability without affecting the (hypothetical) alternate values.
The library does this based on whether a “#” or
“=” character precedes “@”.
According to Strang (1986), the termcap functions were available via the (terminfo-based) curses library. Aside from that, there are few sources which tell when those were added (or whether they were present in the first version of terminfo).
Strang states that Bill Joy wrote the first version of the termcap library, and that Mark Horton wrote the terminfo library. The latter was announced at USENIX (Summer 1982).
There are no copies of the paper online; no useful documentation on this before Strang. The only surviving documents describing this are Horton's Usenet postings. According to Horton:
the version of curses/terminfo in System V Release 2 was frozen in April 1983
Pavel Curtis' reimplementation of terminfo (first mentioned July 1982) did not mention whether it provided a termcap interface (i.e., the function-calls to match the existing termcap library). In his posting to net.general, Pavel described Horton's implementation
At this past week's USENIX meeting, Mark Horton announced the completion of a replacement database/interface for the Berkeley 'termcap' setup. The new version is called 'terminfo' and has several advantages over termcap:
and
Conversion of existing programs from termcap to terminfo is very easy and usually consists mostly of throwing out all of the garbage needed to read and store a termcap entry.
Lacking something more concrete, it is uncertain whether the initial release of Horton's terminfo library provided this either.
Later, in October 1982, Pavel Curtis stated that his reimplementation was ready for testing, and
Compatibility with Mark's package is, obviously, fairly difficult to guarantee, considering that he and I have an ocean of lawyers betwixt us. However, the paper given out at the conference really contained a great amount of information, yielding a pretty coherent picture of what kinds of extensions had been made. At the very least, my package jibes with the info in that paper and with the old package.
The final release of the public-domain package will be timed to coincide with the final 'freeze' on code to appear in the 4.2BSD release, at which time I will make a grand and wonderful announcement on USENET and Unix-Wizards. Before that, though, I would be happy to send tapes to anyone who is willing to run it.
Still later, in
mid-1984, Mark Horton commented on net.unix-wizards
that the SVr2 version provided tgetent
(the “garbage” referred to by Pavel Curtis):
The version of curses/terminfo I have here (and the one distributed with System V Release 2) is upward compatible with termcap at the termlib level. That is, if you have a program that calls tgetent, tgetflag, tgoto, tputs, and so forth, instead of cc foo.c -ltermcap you can type cc foo.c -lcurses and the program will work, using the terminfo database.
In mid-1986, Mark Horton stated on Usenet that he had written the version of terminfo used in SVr2, and that SVr3 "had input" from him. In other words, other people (such as Tony Hansen, author of infocmp) were doing the work from that point. Horton also commented
andThe SVr2 tic was just a modified version of the termcap file reading code, which also doesn't notice syntax errors. The SVr3 tic is completely redone (it's based on Pavel Curtis's tic) and is fairly fussy about syntax errors. It's also more complete, uses the existing binary database, and is much faster.
(For those who are not impressed with tic's error messages, the SVr2 tic, which was frozen for SVr2 in April 1983 along with the rest of curses, is essentially the termcap parser. The SVr3 tic is completely redone, by Pavel Curtis, and it's as fussy as pcc.)
OpenSolaris has sources for captoinfo and infocmp, which give 1984 as the date of creation. Likewise, it has sources for tic, citing Pavel Curtis in 1982.
Interesting enough, InfoWorld in December 1989 had an article by Martin Marshall, entitled Termcaps, Terminfo Frustrate Managers. Marshall (in the context of a discussion with Neal Nelson), wrote
After Termcap files were developed, they were extended differently by nearly every commercial applications developer. The extensions were inconsistent, with the same function being implemented by different key codes on different Termcaps, and the same key code being used to mean two different things by two different programs.
AT&T stepped into the picture three years ago, commissioning the University of California, Berkeley to develop Terminfo, thinking that everyone could standardize upon it.
Strang does not mention color (none of the listed capabilities do color). I may conclude that SVr2 did not support color in spite of subsequent commentary which claims that it supported all of the advanced features such as color, line-drawing, multiple video attributes. Indeed, the InfoWorld article says:
Sam Shteingart, a member of the technical staff at AT&T's Bell Labs responded by listing some of the improvements to Terminfo that have been added with successive releases of Unix System V. Release 3.1, for example, boosted the number of function keys allowed up to 64, while Release 3.2 added the capability to use color in character-based terminals like the Tektronix 4100/4200 families and the HP 2397A. Release 3.2 also added printer support definitions to Terminfo, which involved a substantial rewrite of the LP subsystem.
Strang's focus throughout is on termcap, discussing terminfo
as an alternative. For instance, he comments (chapter 15) that
BSD 4.3 termcap requires that the "tc="
capability be last in a description, noting that it implies that
there will be only one, there is no complementary discussion of
“use=” (terminfo) with any limitations
on position and number.
The terminfo implementations at hand (the SVR4's such as Solaris) all have the same approach to supporting termcap:
tgetent is not modified. The actual terminal
description is stored somewhere else.tgetstr is really a
terminfo string.tgoto is really a
terminfo string.tgetnum is subject to
the limits of a compiled terminfo entry, i.e., positive values
in a signed 16-bit integer which allows 0 to 32767.Although BSD 4.2 is the reference for syntax, most termcap users rely on the later BSD 4.4 libraries. In turn, those have evolved to either use ncurses directly, or have added features for compatibility with it.
FreeBSD's CVS history started in May 1994 (some information
was lost in converting to SVN).
These sections are of interest:
tparm from mytinfo (import in December
1994).FreeBSD getcap was modified to
support “^?” as alias for DEL in May
1995.
Its buffer-size is still 1024 (1023 bytes of data plus a
terminating null).
The base system ncurses is configured to support only termcap; a port supports terminfo.
NetBSD's CVS history starts in March 1993. These sections are of interest:
ZZ capability points to a buffer
containing the full text of the terminal entry,
unconstrained by the 1023-byte limit. The capability is
only used for entries which would exceed 1023-bytes because
it reduces the available space in the 1023-byte buffer
which would be seen by ordinary applications such as
xterm.OpenBSD moved away from BSD termcap early, using terminfo to provide similar functionality.
TERMCAP
and HOME.tgetent to accept a null pointer
for the buffer parameter.The mainstream of development left BSD 4.2/4.3 behind around 1990. There are still some legacy users of the old version, just as there are still developers in 2011 using K&R C or the related "legacy C". This section describes a few examples, all derived from 4.2 or 4.3 code.
The Ingres terminal library is derived from BSD 4.2 code. Comments in the source code indicate that changes started in June 1985, by renaming the termcap file.
While the entrypoints have been renamed, most of the original comments are present without change, even when obsolete. For example
** Essentially all the work here is scanning and decoding escapes ** in string capabilities. We don't use stdio because the editor ** doesn't, and because living w/o it is not hard.
while the Ingres version uses stdio for reporting
errors. Most features (such as escaping) are unchanged. It
provides a few extensions:
tdskip function is used
to access the terminal data as an array of strings, i.e., when
used from the curses library.tgoto recognizes some new operators:
%s
%*
cm (cursor-movement) capability in an
experimental entry for using vt340 in regis mode to access
16 colors.%O
tgoto's new operators fall far short
of terminfo's repertoire. In particular, expressions such as
would be needed for sgr are not supported.
Instead, Ingres' terminal database uses extra string
capabilities which correspond to the 16 combinations of
reverse, blink, bold and underscore. (It uses a different
capability ea for resetting all four of these than
normal termcap would do, sidestepping the problem of the
confusion between termcap's me capability and
terminfo's sgr0.There are a few odd differences in tgoto; the
%i and %2 cases have been moved (an
unnecessary change).
Unlike the other Unix vendors (reduced to HP and IBM), Sun (now Oracle) has long provided a compatibility library based on BSD source. This is from BSD 4.3 rather than the more common BSD 4.4 version. Because it is provided for compatibility and is not actually a supported product, there is no documentation.
OpenSolaris has a few legacy uses of termcap (UCB curses of
course), as well as programs in ucbcmd such as
tset:
/* Copyright (c) 1979 Regents of the University of California */ /* Modified to: */ /* 1) remember the name of the first tc= parameter */ /* encountered during parsing. */ /* 2) handle multiple invocations of tgetent(). */ /* 3) tskip() is now available outside of the library. */ /* 4) remember $TERM name for error messages. */ /* 5) have a larger buffer. */ /* 6) really fix the bug that 5) got around. This fix by */ /* Marion Hakanson, orstcs!hakanson */
Note also that
tskip is made available (for use in the main captoinfo
program). It does not improve on the original BSD 4.1
implementation, which lacks a check for the buffer size.
Fixing tskip by itself would not make the
termcap code safe from buffer overflows; the logic used
"tc=" resolution also has multiple issues. But
exporting tskip without providing for
buffer-limit checks compounds the problem.
tgetent function asks the
operating system for the terminal's current size, and sets the
li (lines) and co (columns)
capabilities in the returned data. Linux termcap 2.0.8 by the
way does the same thing (but OpenSolaris has no history before
2005, making it impossible to gauge which implementation had an
effect on the other).This library was first published in December 2007. Some files have older modification times, none older than 2001.
Jörg Schilling uses BSD 4.3 termcap with some minor
enhancements (see current
site—ftp
site is defunct). It provides support for TERMPATH
which was introduced in BSD 4.3, but the implementation is
slightly different, to avoid using BSD-specific names.
The extensions (there is no documentation other than the C source) include:
malloc'ing a copy of the TERMCAP
value when using it as a terminal description.realloc the working copy of
the terminal description, to allow it to grow temporarily,
e.g., when expanding a "tc=" capability. The
resulting description still is decoded subject to a limit-check
against 1023 however.tgetent expands multiple "tc="
includes, not limited to one at the end of the buffer.tgetent adds the terminal's size
to the returned data.tgoto is modified slightly:
%C (cited from GNU) emits parameter/96,
parameter%96.%m (cited from GNU) XOR's both parameters
with 0177.tcsetflags is provided, which
allows an application to control whether
tc=" includes are processedtskip, but without providing buffer-limit
checks.Like all variants before BSD 4.4, it has bugs in the
checks for buffer-overflow (including the longstanding problem
with tskip). I made these changes for example to
eliminate core-dumps from the library while investigating it with
tctest:
--- tgetent.c.orig 2010-10-12 18:10:20.000000000 -0400
+++ tgetent.c 2011-08-04 20:57:40.000000000 -0400
@@ -91,6 +91,7 @@
EXPORT BOOL tgetflag __PR((char *ent));
EXPORT char *tgetstr __PR((char *ent, char **array));
EXPORT char *tdecode __PR((char *ep, char **array));
+LOCAL char *mytdecode __PR((char *base, char *ep, char **array));
#if defined(TIOCGSIZE) || defined(TIOCGWINSZ)
LOCAL void tgetsize __PR((void));
LOCAL void tdeldup __PR((char *ent));
@@ -351,6 +352,7 @@
BOOL needfree;
char *xtbuf;
int ret;
+ int tst;
if (tbuf == NULL)
return (0);
@@ -404,7 +406,8 @@
/*
* Add nullbyte and 14 bytes for the space needed by tgetsize()
*/
- ret = ep - otbuf + strlen(np) + 1 + TSIZE_SPACE;
+ tst = strlen(np);
+ ret = ep - otbuf + tst + 1 + TSIZE_SPACE;
if (ret >= (unsigned)(tbufsize-1)) {
if (tbufmalloc) {
tbufsize = ret;
@@ -422,7 +425,8 @@
ret = tbufsize - 1 - (ep - otbuf);
if (ret < 0)
ret = 0;
- np[ret] = '\0';
+ if (ret < tst)
+ np[ret] = '\0';
}
}
strcpy(ep, np);
@@ -600,7 +604,7 @@
if (!ep || *ep == '@')
return ((char *) NULL);
if (*ep == '=') {
- ep = tdecode(++ep, array);
+ ep = mytdecode(tbuf, ++ep, array);
if (ep == buf) {
ep = tmalloc(strlen(ep)+1);
if (ep != NULL)
@@ -620,10 +624,11 @@
* Note that old 'vi' implementations limit the total space for
* all decoded strings to 256 bytes.
*/
-EXPORT char *
-tdecode(pp, array)
- char *pp;
- char *array[];
+LOCAL char *
+mytdecode(
+ char *base,
+ char *pp,
+ char *array[])
{
int i;
register Uchar c;
@@ -633,7 +638,7 @@
bp = (Uchar *)array[0];
- for (; (c = *ep++) && c != ':'; *bp++ = c) {
+ for (; ((ep - (Uchar *)base) <= 1023) && (c = *ep++) && c != ':'; *bp++ = c) {
if (c == '^') {
c = *ep++ & 0x1f;
} else if (c == '\\') {
@@ -662,6 +667,17 @@
return ((char *)ep);
}
+/*
+ * Workaround to let the various callers work no worse than before...
+ */
+EXPORT char *
+tdecode(
+ char *pp,
+ char *array[])
+{
+ return mytdecode(pp, pp, array);
+}
+
#if defined(TIOCGSIZE) || defined(TIOCGWINSZ)
/*
Incidentally, I noticed this comment by Schilling while researching the two-character termcap quirk (present here as well) for Debian #698299:
At the same time, hundreds of bugs in the Dickey termcap file
have been fixed. It seems that Mr. Dickey now uses our termcap
program to verify the content of the file for correctness.
However, I did not incorporate any aspect of Schilling's test-program into tctest. It was not useful.
On the other hand, Schilling used ncurses in his test program.
It consists of two files (cap.c and
caplist.c).
Schilling copied the latter from ncurses 5.2 source code:
include/Caps:
I noticed and commented on this when Schilling first announced the program in early 2008 on FreshMeat:
termcap program
What's a "compiled" termcap? (By the way, Solaris termcap - which I would have thought this would use - uses a few different names than ncurses, and the comments in schily-2008-01-10/termcap/caplist.c are from ncurses ;-).
Comparing with Solaris documentation:
include/Caps file,max_attributes).back_color_erase as be.ut.In discussing GNU termcap, I am considering three versions:
The 2.0.8 and 1.3.1 versions competed for at least ten years. Your system may have either, depending on the packager's preferences and ambition.
The former provides both shared and static libraries for
Linux; the latter only provides a static library. The 2.0.8
version also (like Solaris) returns the terminal's size in the
data from tgetent, while the 1.3.1 version only
mentions in its documentation that an applicaton ought to do
this.
The 1.3.1 and 1.3 versions are very similar (aside from updating the termcap file). The documentation describes 1.3; this discussion focuses on the extensions.
GNU termcap
tparam which is
tgoto prototyped with a variable argument list and
the ability to specify the buffer into which formatted text is
stored. The variable argument list support does not use
<stdarg.h> and is not portable. Rather, the
function assumes four integer parameters.tgetent accepts a null buffer parameter, will
then allocate 2048 bytes.tgetent
to accept multiple "tc=" capabilities. For
example, the SuSE package for 2.0.8 does this.tgoto adds several extensions:
%C emits parameter/96, parameter%96.%f tells tgoto to ignore the
next parameter.%b tells tgoto to reuse the
previous parameter.%a provides arithmetic operations, like
terminfo.%m XOR's both parameters with 0177.tgetstr and related functions which
retrieve capability values use a slightly different comparison
which assumes that the names are always two characters (no
special quirk for a single-character name). However, there is a
corresponding quirk in the match for boolean names: it is
possible to retrieve a single-character boolean value if the
caller passes “:” as the second character of the
name, and if the termcap has a double-colon at that point.At one point, ncurses had a tparam function (from
changes by Eric Raymond in January 1996). But this symbol
conflicted with emacs, and Eric removed it.
ncurses reads either termcap or terminfo source files,
compiling those to terminfo format. It has been more forgiving of
differences from BSD 4.3 syntax than some other
implementations. For example, I added fixes early in 1998 to fill
in missing parts of the terminfo syntax (the \a and
^0 items noted here. Those also affected the
termcap parsing. Much later, I added a strict option to
tic which suppresses those translations.
As terminfo supports multiple "use=" capabilities (the same as
"tc=") capabilities), ncurses also supports multiple
"tc=" capabilities.
ncurses recognizes the GNU termcap %m, but none
of the other extensions for the simple reason that no substantial
termcap source was ever written using the GNU extensions. GNU
termcap has always distributed either Eric Raymond's (mostly
generated) termcap source, or one wholly or partly derived from
ncurses.
I have used termcap since 1983. At the time, I was more interested in curses than termcap, since curses (poorly documented) was the visible interface used for dired. However, in my lab, I had a BitGraph terminal, and at home an Ann Arbor Ambassador terminal. Both had some VT100-compatibility, but both had interesting extensions that could be used by customizing a termcap entry. Initially, this was for simple things, such as setting the screen size. I was interested in using termcap to support the graphics work that I did with the BitGraph terminal, but on asking advice, was told "termcap doesn't do that sort of thing".
Shortly after, I moved to a different project. I was allowed to retain the Ann Arbor terminal but most of my work was using Apollo workstations, with some tie-ins to VAX/VMS and PrimeOS. None of that involved termcap.
Later (in 1986), I used Wyse-50 terminals in development on an SVr2 system. At the time, I knew only about termcap. The SVr2 system supported terminfo, but I did not modify it. The terminal database's entry for the Wyse50 (probably "wy50") was good enough for vi. It did not mention that the terminal has programmable function keys (and labels). So I wrote a special-purpose (C) program to set up the terminal.
It was not until the mid-1990s that I really got involved in the development of termcap, rather than being a user. That was with ncurses, of course. Even still, until mid-1996 I refrained from doing much with the tools (tic, infocmp) which manipulated terminfo and termcap. At that point, I realized that making ncurses successful required improving all parts of the system.
It helped that I got useful feedback—mostly from various BSD developers. My email shows these for instance:
I have improved ncurses' support for termcap in three areas:
I addressed this by making ncurses able to define new capabilities using the terminal description. Standard capabilities are unaffected; new capabilities are optional.
Quoting from my email to Florian La Rouche (1999/2/21):
> > I have a couple of minor changes also (I overlooked one item in define_key, > > and am considering adding a small change to allow us to extend the terminfo > > format later without causing the existing applications to refuse to recognize > > the new format). > > That sounds like a very good feature to add before a release. (as long as it doesn't break old programs ;-) I am considering adding a 5th table to the file format and making the terminfo reader smart enough to “see” it in what would be unused space after the existing tables. Several people have complained that terminfo cannot be extended; allowing it to store extended capabilities would alleviate that.
This made the TERMTYPE structure
binary-incompatible. It is implicitly used by any low-level
application that includes <term.h>. This
feature, together with some interface corrections to match
the X/Open Curses specification were the reason why the
ncurses release numbering jumped from 4.2 to 5.0 (the release
numbering is determined by binary compatibility).
The reason why this change improves ncurses' support for termcap is that there is only one source for terminal descriptions in ncurses. Eric Raymond had three sources, relying on manual fix-ups to get usable termcaps:
tic. Essentially, tic would omit
capabilities not part of standard terminfo.tic program, then
followed up with shell scripts and manual edits.Raymond reused code from Ross Ridge's public domain
mytinfo package (comp.sources.unix, volume 26,
issue 77, December 1992) for these features:
However mytinfo did not convert from terminfo to termcap format. This was an area that Raymond started, which I have continued, making mechanically generated termcaps usable in most instances.
The changelog in the termcap 1.3.1 package states that it
uses termcap.src regenerated from (Raymond's) 11.0.1 master
file. The "regenerated" part was done using ncurses'
tic program, to resolve the "tc="
references. The translation also relies on the improvements
that I made to tic up to that point (early
2002).
tc=" capabilities (includes).
OpenBSD added hashed database for their system version of
ncurses in
1999. Again, this stores text — this time for
terminfo. It means that the library must contain most of the
tic terminfo compiler. One of the features of
terminfo in comparison to termcap is that terminfo is
compiled and loads into a usable form with less
work. Also, in contrast to ncurses, the OpenBSD design uses
cap_mkdb to load the entire database at one time
rather than providing from incremental loading from various
sources.
I added support for hashed databases in 2006. Like other
features of ncurses it is reasonably portable (in this case
relying upon Berkeley Database), and stores terminal entries
in compiled form. Berkeley Database allows records longer
than 1024 bytes (unlike
ndbm on Solaris for instance). Equally important, its
licensing is non-restrictive, unlike ndbm and
gdbm.
The original implementation (of BSD 4.3) termcap has several problems:
The design of termcap assumed that the calling application would be more efficient by providing a fixed-size buffer to return the data than by using malloc. Recalling that 1023 bytes seemed "big enough" in that era, it has proven too cramped for terminals with multiple function keys. In particular, the widespread PC keyboard with 12 function keys, multiple modifiers and more sophisticated applications has made 1023 seem too small.
But in 1979, a 1023-byte buffer was also fairly large on the small machines that Unix ran on. That may explain why wasted space within that buffer was overlooked. When BSD 4.3 termcap reads data into the buffer, it reads everything. It does not discard the whitespace and extra colons which are not actually part of the terminal description. Reduce that 1023-bytes by 3%.
Some applications such as xterm (depending on the system) and
screen may set the
TERMCAP environment variable to exploit another
feature of the termcap library: if it is set to something that
looks like a termcap description, that is used as the
terminal description. If you happen to be using a system which
does this, you might have noticed that it is formatted as several
lines. For xterm, that would happen with a
BSD 4.3 termcap (screen is perverse and does
this all the time).
Mark Horton argued against the use of environment variables:
>A termcap database sorted approximately in >decreasing order of frequency of use should be at least as fast as the >repeated directory lookups required to descend the terminfo tree -- and >termcap format is *trivial* to parse. > >If speed is what you want, sort /etc/termcap in decreasing order of >frequency of use. If that's not good enough for you, cram your termcap >definition in the environment variable TERMCAP and leave terminfo behind >entirely, when it comes to speed. I used to think this too. I was at Berkeley when we decided how to sort termcap files and put them into the environment. It helped a lot. But it turns out that even if you put a termcap in your environment, it's still too slow. The termcap algorithm for reading the entry into a set of capabilities is QUADRATIC on the size of the entry. This is the nature of the beast - because of tc=, you have to start from the left for each capability search. As termcap descriptions got longer, starting up vi grew slower and slower. It was taking 1/4 second of CPU time on a VAX 750 to parse the termcap entry, even when it came out of the environment. This was when I decided to move to a compiled format. Things get much simpler for the typical user - no need for the whole entry in the environment anymore, or the hair of tset -s in the .profile/.login. The ps command was breaking from the huge environment entries that took the arguments off the top page of memory. Forks were expensive. And it took too long to start up vi. All these problems went away when terminfo was compiled.
Besides wasting process space, a multi-line
TERMCAP variable complicates shell scripts. In
contrast, BSD 4.4 discards the unnecessary characters,
resulting in a single-line value.
Different implementations use additional workarounds to increase the effective buffer size for a terminal description; no particular scheme is used for all of these.
With some care, it is possible to fit usable terminal
descriptions into the 1023-byte limit. The termcap library does
some simple checks to keep from writing past its caller's buffer.
However, the "tc=" (includes) are a little more
complicated than the program can handle, making it possible to
chop a capability at the end of the buffer, giving odd results.
The termcap library's handling of buffer overflows has other
bugs, allowing it to write past the end of the buffer anyway.
When reporting problems in a termcap entry, the library uses
only simple messages, calling write rather than
printf. According to comments in the code, the
library did not use <stdio.h> because the
editor (vi) did not. As a result, termcap error messages
do not provide names of too-long entries.
The termcap library implements inheritance by replacing the
"tc=" capability at the end of the termcap entry
with the included text. (It does discard the name and description
of the included entry, but rather than being for efficiency, that
is done because of syntax restrictions). A capability could
appear in both the original and included entry. The text for both
is stored in the same 1023-byte buffer, and the library has to
search for the first occurrence. Because of the duplication, the
effective buffer size is again reduced, and searches for the
first occurrence of a capability are longer than necessary.
Fortunately, termcap buffer sizes are small; the performance issues are not as noticeable as they were in older machines.
Later implementations, e.g., BSD 4.4, support multiple
"tc=" capabilities. Again, the inheritance is purely
textual. To get efficient storage, a scheme such as that used by
terminfo is needed. With terminfo, the capabilities are merged
into an array, which eliminates the need for juggling and
recopying the entry as "tc=" includes are
processed.
Rather than being designed, it appears that termcap "just grew". The handling of escapes in particular is uneven (see table of escapes). For instance:
tskip function (used to skip forward
through an entry) does not pay any attention to escaping. This
requires that colons used as data must be given as octal
"\072" and handled in a later part of the
parsing.tskip had paid
attention to escapes, the check for colon would succeed at that
point.tc=" is done with a
mixture of forward- and backward-scanning. As with the
forward-scanning (tskip) the backward-scanning
does not pay attention to escapes, ensuring that an embedded
"tc=" in a capability's value will be
misinterpreted.# set to page 1 when entering ex (\E-17 )
# reset to page 0 when exiting ex (\E-07 )
v4|tvi912-2p|tvi920-2p|912-2p|920-2p|tvi-2p|televideo w/2 pages:\
:ti=\E-17 :te=\E-07 :tc=tvi912:\
v5|tvi950-ap|tvi 950 w/alt pages:\
:is=\E\\1:ti=\E-06 :te=\E-16 :tc=tvi950:
Later implementations of the termcap parser resolved some of
its problems by first splitting the termcap entry into an array
of strings to use consistent boundaries. That helps with
"tc=" parsing. However the original misdesign of
tskip is carried forward. Legacy implementations
(such as Solaris) are unimproved.
Using tctest, I found that the parsing for escaped colons is incomplete and inconsistent.
For instance, this example:
is translated to this:O0|Octals|test octal-escapes:\
:F9=a\472:\
:FA=a\472FB=\333:\
:FB=a\134:\
:FC=a\::\
:FD=a\:FE=\333:\
:FE=a\134:\
:FF=a\072:\
:FG=a\072FH=\333:\
:FH=a\134:\
:is=\EZ:
# alias E0
Octals:\
:F9=a\072:\
:FA=a\072FB=\333:\
:FB=a\\:\
:FC=a\072:\
:FD=a\072FE=\333:\
:FE=\333:\
:FF=a\072:\
:FG=a\072FH=\333:\
:FH=a\\:\
:is=\EZ:
The "\:" in the definition for FD is
translated to an actual colon, and the value returned includes
the shadowed FE, contrary to the termcap manpage
which says that literal colons must be given as
"\072". That is because escapes are checked in
forward-scanning, but not in backward scanning.
The mapping of "\472" to "\072" is
expected, and it happens to match the treatment of
"\:".
The sequence "\0" also is mishandled by
BSD 4.3 termcap. If one uses that in an entry, it loses
track of the actual character position (due to the inconsistent
scanning) and acts as if the characters following the misencoded
null are part of the capability. If the first of those happens to
be the delimiting colon of the capability, it becomes
part of the value. In some cases, a garbage character is added
for completeness. Not only that capability value is misparsed,
but others which follow it in the entry. The
escapes.tc test case shows this behavior, in the
Octals entry.
Oddly enough, the equivalent "^@" is handled as
one might expect from the documentation, and thrown away.
Modern (since 1990) implementations of termcap provide extensions.
Rather than rely on documentation (which can be interesting), I have set up test-cases with tctest to verify whether a given implementation reads a particular syntax feature, and how it is returned to a calling application.
Because ncurses can read termcap source files, it is
technically a termcap implementation. It stores the terminal
entries in terminfo format, but at the same time it provides
better support for termcap applications than other terminfo-based
implementations. Much of that is because of reports from
screen's developer Michael Schroeder. For
instance
tgetstr for the "me"
parameter.me" and
"sgr0" are equivalent. However, Michael Schroeder
pointed out that termcap applications do not expect to have
this capability modify the state of the alternate character
set.NetBSD termcap (deprecated in 2010 in favor of a native
terminfo implementation) provides the BSD 4.4 extensions.
They are actually not in the termcap library, but rather
are provided by cgetstr (originally May 1993), which
is in src/lib/libc/gen:
Source Result \B backspace \C colon \F form-feed \N newline \R return \T tab \c colon \e escape
However there is some breakage, making it incompatible with BSD 4.2 termcap (testing NetBSD 5.1):
Source Result \b is eaten \t is eaten \072 is eaten
Neither flavor (2.0.8 or 1.3.1) documents the features that are of interest.
Termcap 2.0.8 ignores the termcap entry's lines and columns
values, replacing those by the actual screensize in
tgetent.
It does not honor the \072 escape. Both
\072 and \: are interpeted as a
separator.
Like the BSD termcap implementations, it dumps core when processing too-large entries.
Termcap 1.3.1, on the other hand, does not dump core for the examples in tctest.
Termcap 1.3.1's handling of escapes is loosely based on BSD 4.4's extensions:
Source Result \A ^G \B \b \F \f \N \n \T \t \V ^K \a ^G \e \E \v ^K \08 (eaten) \09 \t \134 (garbage) \8 \b \9 \t
In addition to using tctest to check for syntax issues with different termcap implementations, it is useful (simply because it retrieves all of the terminal descriptions from a source) for comparing performance.
Using different command-line options, tctest can be told to
tgetenttgetstr (and tgetnum,
tgetflag) for all possible capability names,The measurements reported here are from tctest's "make check", "make check-cap" or "make check-tic" rules. The "check-cap" and "check-tic" makefile rules tell the test script to store each termcap file as a database, either hashed (for the BSD's) and/or file-system (for ncurses). The tests are designed to work on a large terminal database, getting data from a variety of terminal entries. Other types of tests are possible, but not currently of interest in this discussion.
There are several configuration choices for ncurses. It can read a flat file, but that is the least efficient. The comparison with BSD 4.4 hashed databases is the most interesting; data from the older flat file implementations are shown for comparison. To configure ncurses with support for termcap, I used these options:
--enable-getcap --enable-termcap --enable-bsdpad
Mark Horton's 1986 comment on Usenet says he found parsing $TERMCAP to be slower than reading binary terminfo from a file, simply because of the cost of parsing it, irregardless of the storage mechanism. That might be interesting in another discussion; however distinguishing file access times from disk-caching complicates it.
I have five systems that I can get interesting timing figures for:
Actually I have other systems, but those would duplicate things without adding information. Here are some issues that are relevant to the comparison:
Of course, ncurses is available on each platform, while the others (except for the four variants which I compiled for Debian) are available only on specific platforms. The timing figures are subject to the usual caveats:
All times are in seconds (real time), and are for one of the
test-files (the BSD 4.3 termcap file, which is about 167Kb).
The test file was chosen because it was the largest one having no
multiple "tc=" includes. Also, no entries are too
large. That makes the test work with the older termcap
implementations.
tgetent.
System Library Database Test tgetent*10 Test standard caps Test all possible caps Debian 5.0 ncurses filesystem 0.72 1.42 19.29 Debian 5.0 ncurses hashed-db 0.32 1.40 19.75 Debian 5.0 BSD 4.2 flat file 18.16 7.80 106.47 Debian 5.0 BSD 4.3 flat file 12.54 4.15 50.13 Debian 5.0 schily-2011-06-22 flat file 14.94 5.20 54.59 Debian 5.0 termcap 2.0.8 flat file 11.42 3.90 47.48 Debian 5.0 termcap 1.31 flat file 13.86 6.20 85.68 FreeBSD 4.9 ncurses filesystem 0.63 2.00 29.91 FreeBSD 4.9 ncurses hashed-db 0.49 1.98 29.50 FreeBSD 4.9 termcap hashed-db 2.11 2.43 44.71 FreeBSD 8.1 ncurses filesystem 6.20 2.30 27.80 FreeBSD 8.1 ncurses hashed-db 0.37 1.79 26.38 FreeBSD 8.1 termcap hashed-db 5.03 3.43 57.19 NetBSD 5.1 ncurses filesystem 0.78 1.31 17.60 NetBSD 5.1 ncurses hashed-db 0.50 1.29 17.33 NetBSD 5.1 termcap hashed-db 0.65 3.43 52.01 NetBSD 5.1 curses hashed-db 0.65 3.11 51.31 OpenBSD 4.9 ncurses filesystem 5.90 1.70 64.50 OpenBSD 4.9 ncurses hashed-db 0.53 1.22 63.70 OpenBSD 4.9 otermcap hashed-db 3.84 2.81 160.26 OpenBSD 4.9 curses hashed-db 3.84 2.81 160.24 Solaris 10 ncurses filesystem 4.11 2.49 31.01 Solaris 10 ncurses hashed-db 0.54 2.07 30.18 Solaris 10 ucblib flat file 14.53 5.51 67.87
The table illustrates some of the performance differences within a given platform, showing that hashed databases are more effective on some platforms. Similarly, there are differences between different termcap implementations; some use more efficient methods for retrieving capability information.
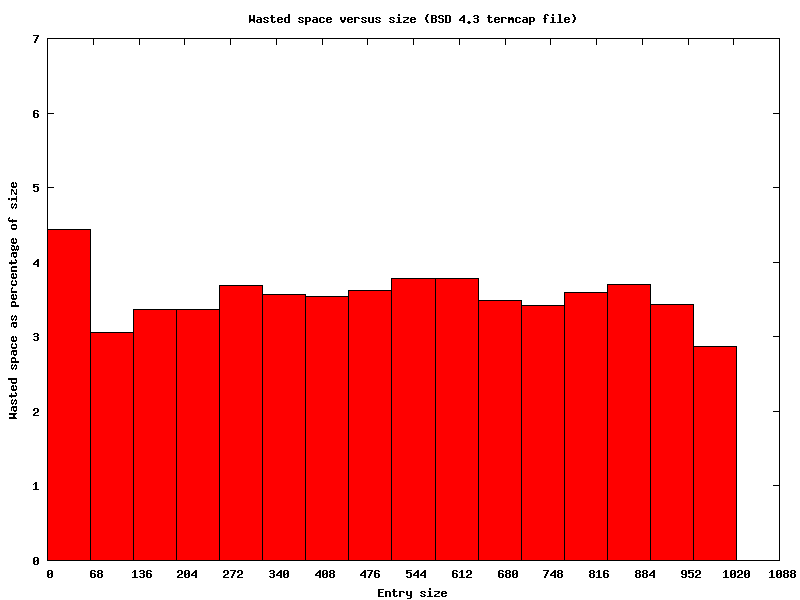
The BSD 4.3 termcap library wastes space by not
discarding the unnecessary whitespace used to make it simple to
edit. Generally this is about 3% of the text returned by
tgetent, as illustrated:
The output from tctest would then waste even more space (if used as a termcap datafile) simply because it uses a separate line for each capability. BSD 4.4 and ncurses are unaffected by the extra whitespace, discarding it as they read the datafile.
Peter Wemm pointed this out to me early on, saying that BSD 4.3 had many known bugs and was slow, and that BSD 4.4 had fixed most of those problems. Keeping that in mind, the memory limitations of BSD 4.3 are not generally an issue, and that problems due to "large" termcap entries are mainly a concern to secondary users of ncurses' terminal database.
For instance, I provide a link to a generated termcap source on my ncurses page. The generated termcap matches the general structure of the terminfo source from which it is generated:
use capability in the terminfo is a
tc in the termcap,tc=" will often exceed
1023 bytes.Primary users are those who are using ncurses or some other termcap library (such as NetBSD) which can handle that generated termcap file.
Secondary users on the other hand are developers using a different termcap library.
The developers of GNU termcap 1.3.1 used different options of
tic to resolve multiple "tc="
capabilities, and to relax the limit on entry size. They noted
that entry size is not a problem with their library, and that
users who need the data from tgetent should allocate
a buffer at least 2500 bytes.
Other developers may wish to experiment with BSD 4.3 (or equivalent). Using ncurses' tic, it is simple to generate a termcap source which is trimmed down enough for that , e.g.,
tic -Cr0 terminfo.src >termcap-file
The "-r" option has been part of ncurses for
quite a while. I added the "-0" option to
tic in 2011, while developing this
program.
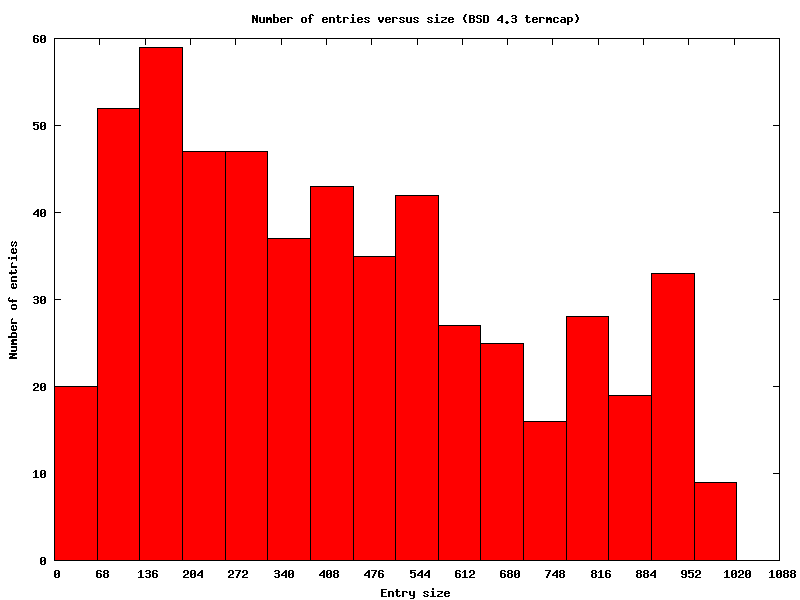
Of course, working within the 1023-byte limit ensures that some functionality is lost. It was a noticeable problem even with the BSD 4.3 terminal database. The plot below (using gnuplot) shows that the distribution of entry-sizes is bimodal:
The second peak includes terminals such as the Ann Arbor Ambassador and the Concept terminals–widely used improvements over VT100's.
Since BSD 4.3, the terminal database has grown, both in number of entries and the size of the entries.
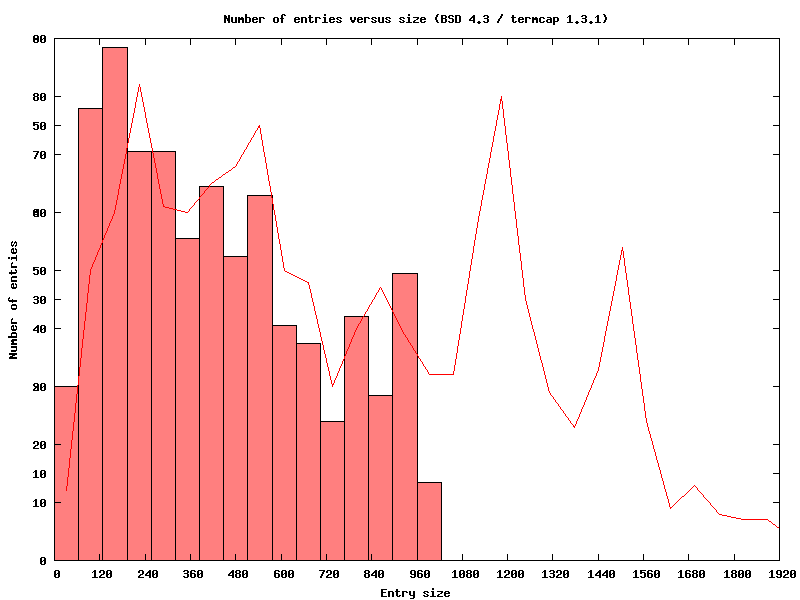
For example, here is the same BSD 4.3 plot with a line showing the termcap 1.3.1 data.
It is easy to see that the entry-size distribution has shifted off to the right, and that newer terminals simply have too many features to use effectively within the old limit. Redrawing the same chart with ncurses would be less interesting, since the BSD 4.3 data is still smaller in relation to the current database.
tctest (pdf) (postscript) (plain text)