http://invisible-island.net/luit/
Copyright © 2013-2017,2021 by Thomas E. Dickey
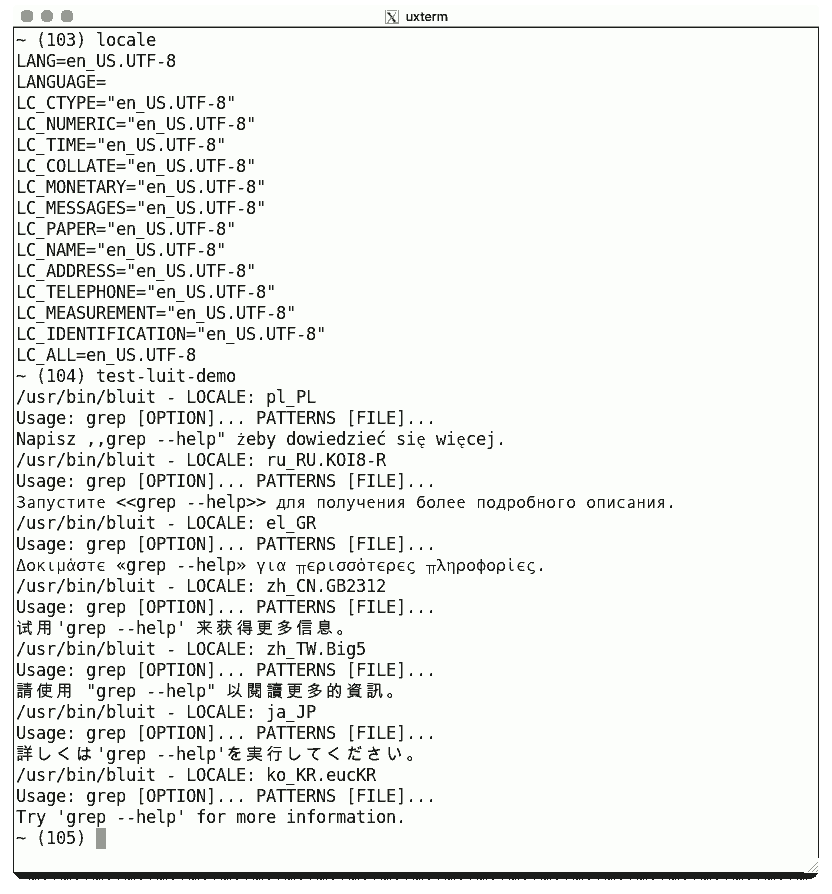
On Chroboczek's webpage, he shows
luit being used to run the grep
command in a succession of locale settings which do not use
UTF-8. Luit translates the input/output of the
grep process, making its messages have UTF-8
encoding. Here is a reconstructed image, showing my UTF-8 locale
and the results for each message:
At the time Chroboczek began writing luit there were several people interested in adding UTF-8 support to xterm. Most were uninterested in providing support for legacy applications.
I was, of course. Not all character encodings have a mapping to UTF-8, and not all applications produce UTF-8.
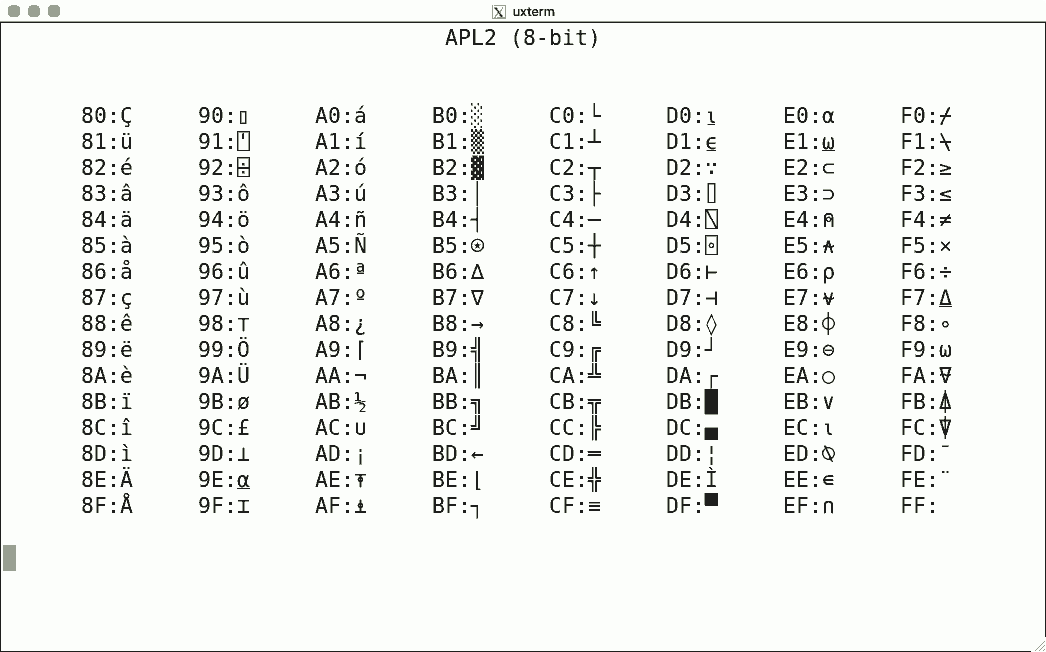
Related to terminal character-set support, there is the example of DEC's VT100, VT220 terminals. In the figure below, most of those odd-looking backwards-"?" marks correspond to DEC characters for which there was no corresponding Unicode code point.
DEC Character Sets 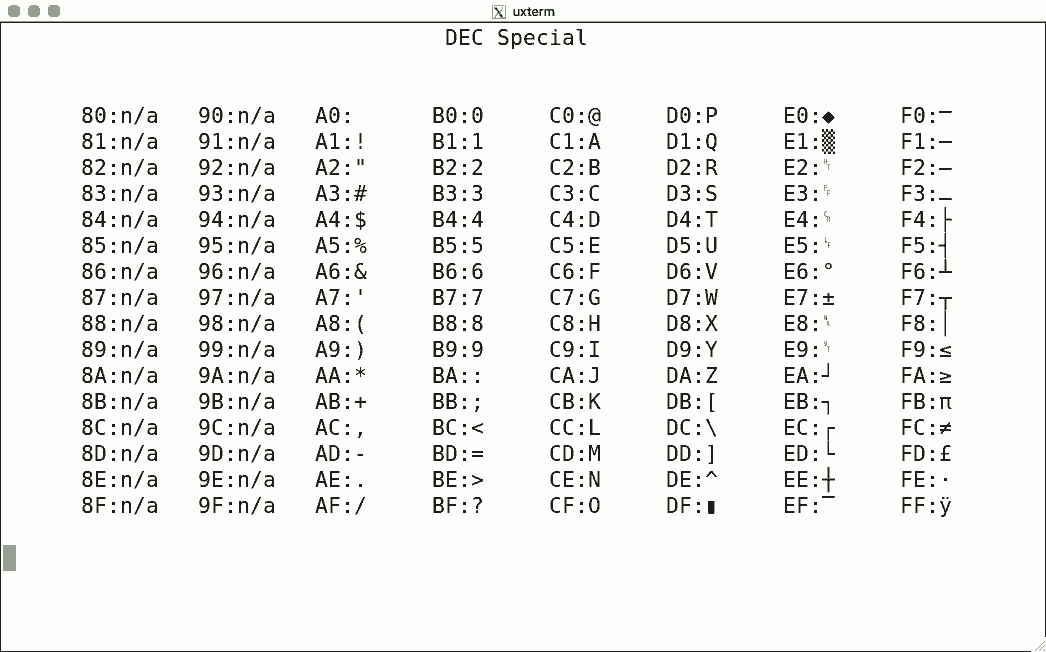

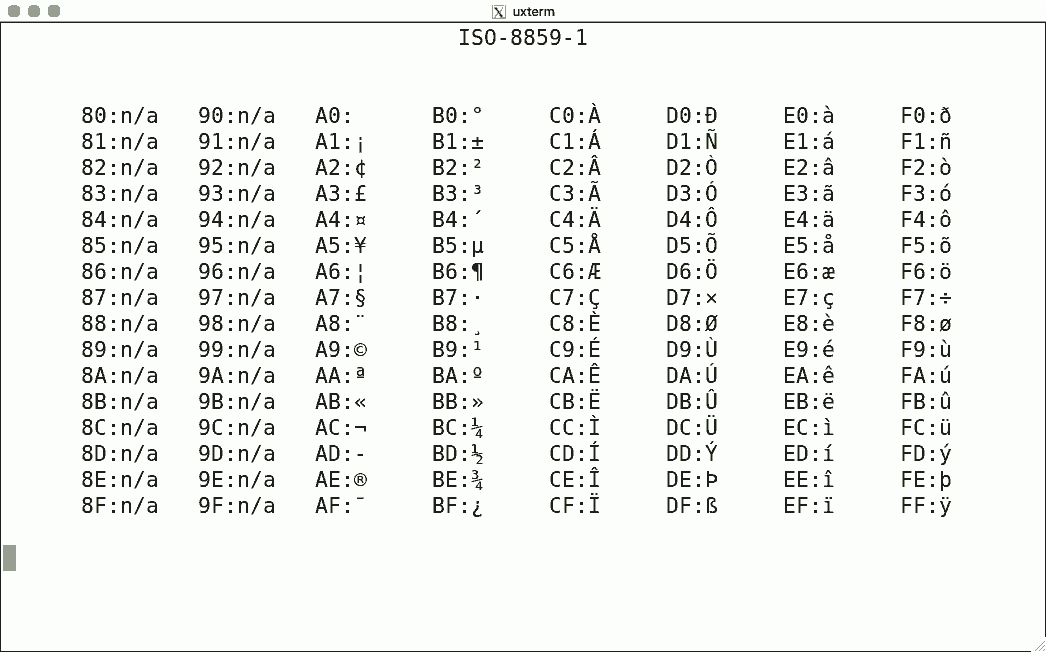
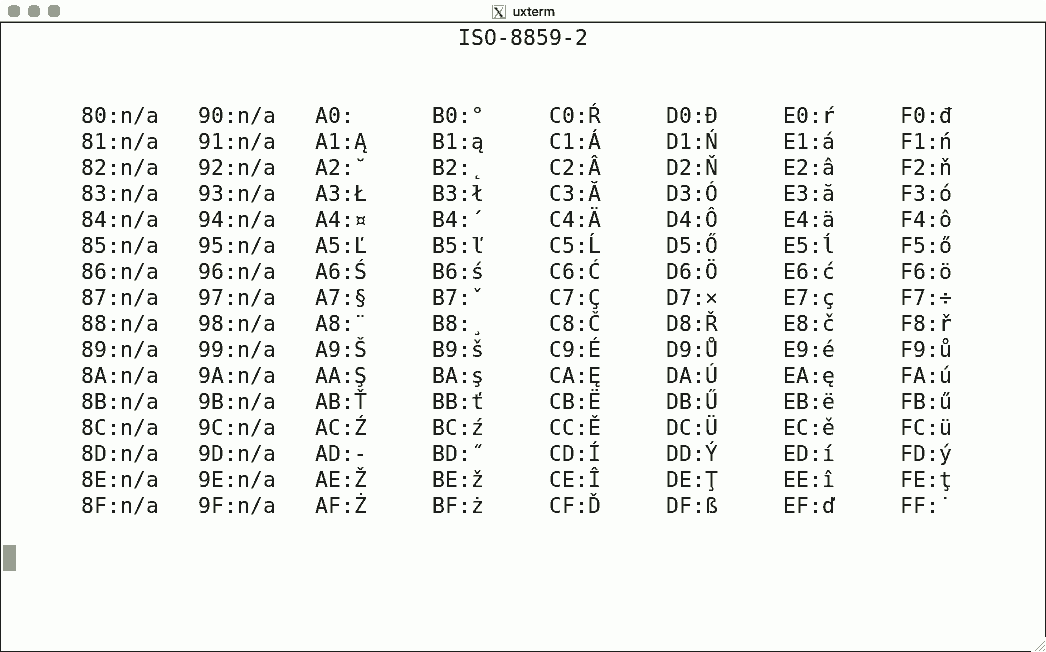
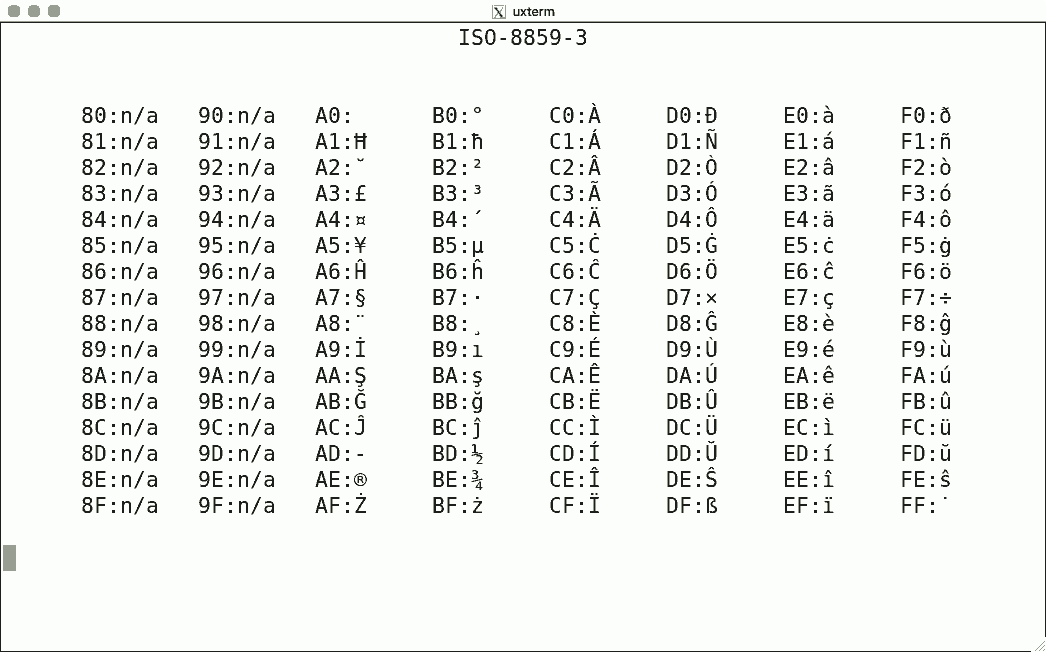
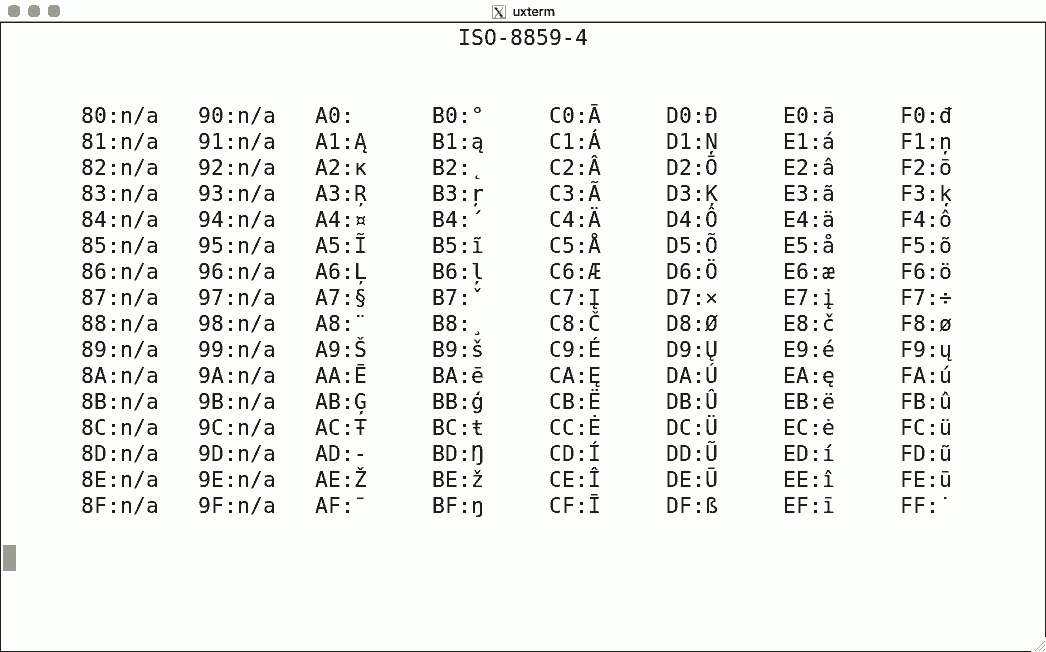
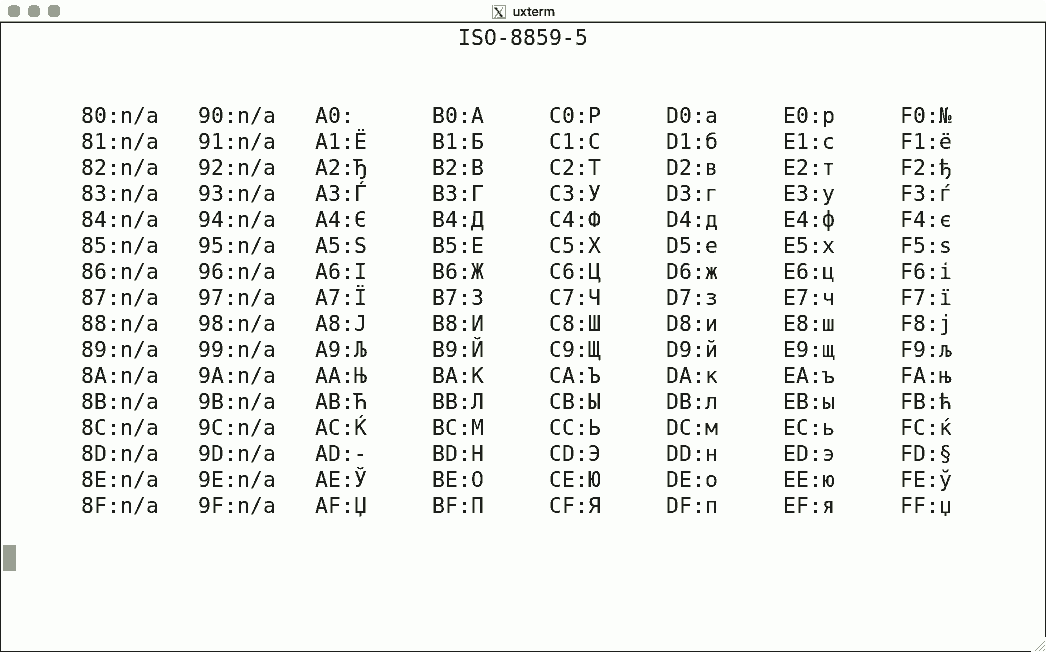
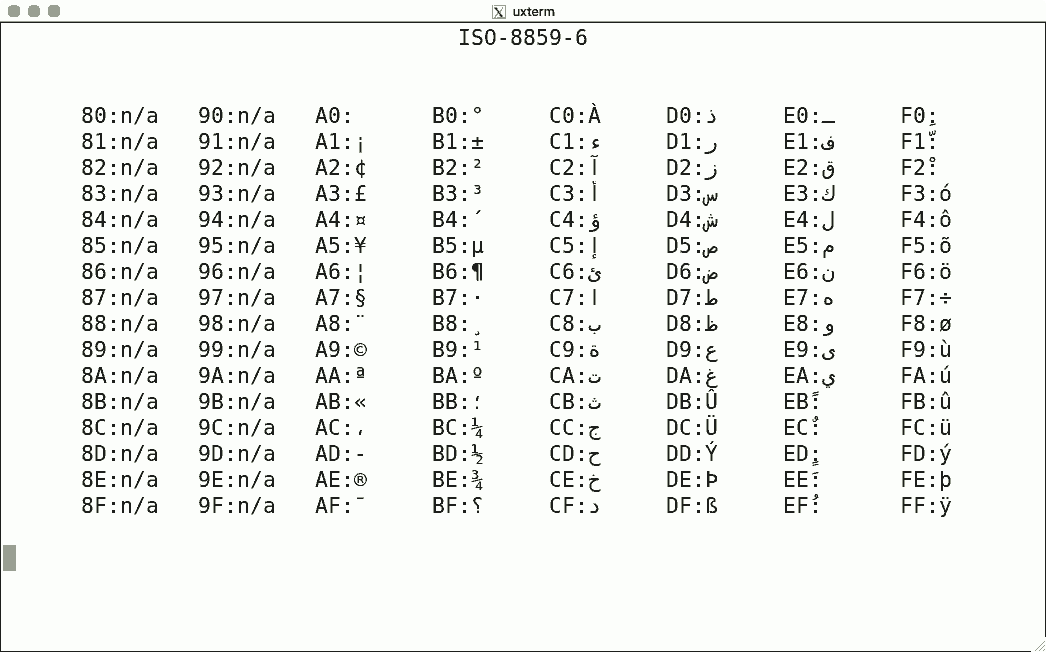
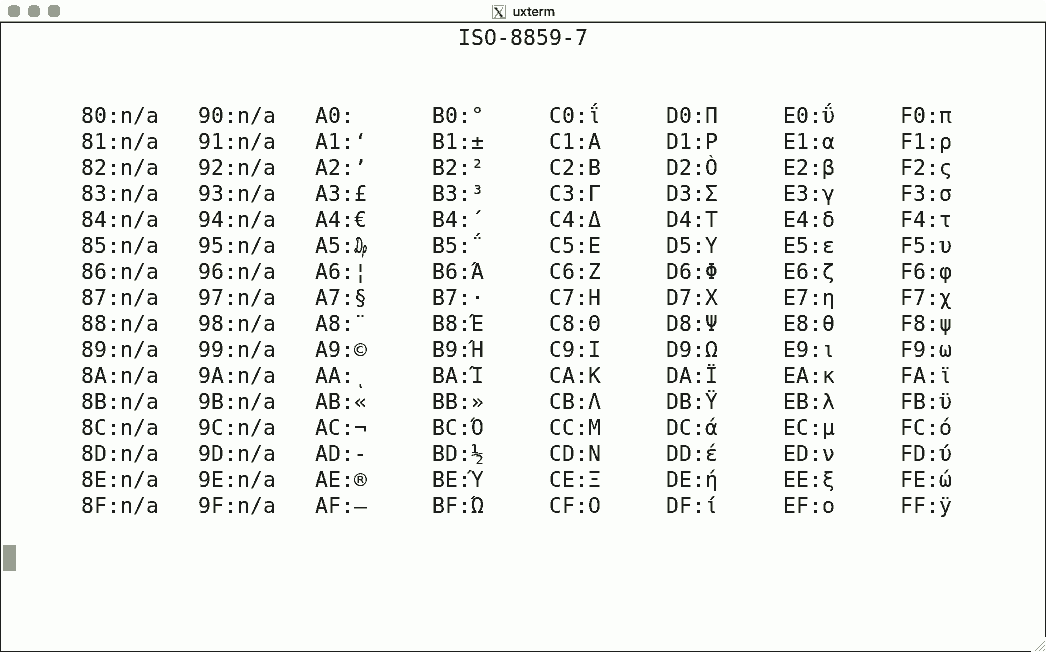
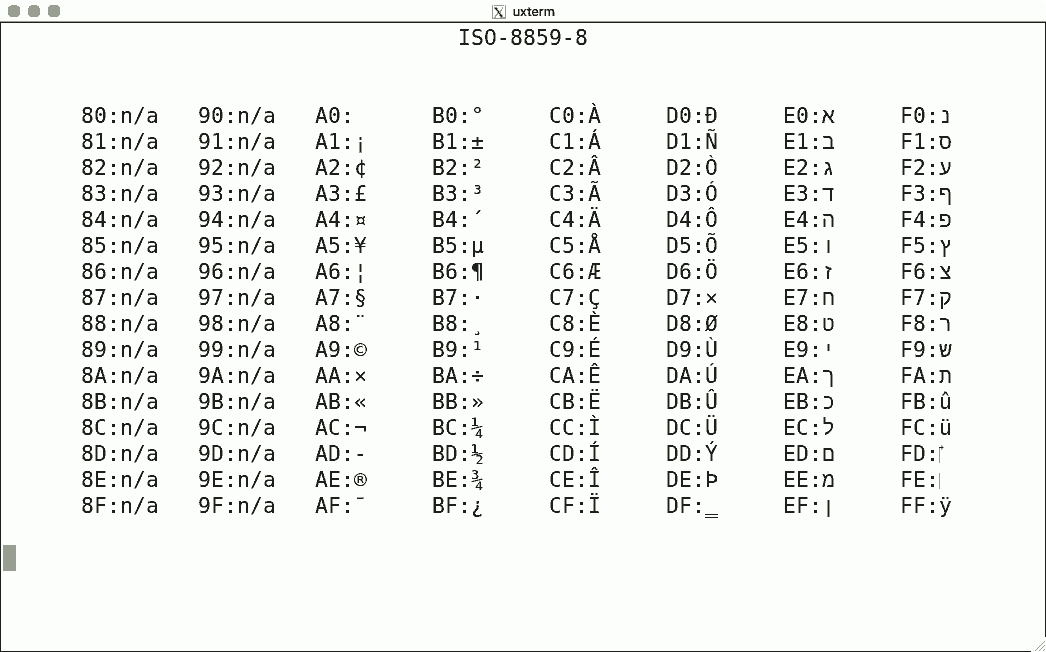
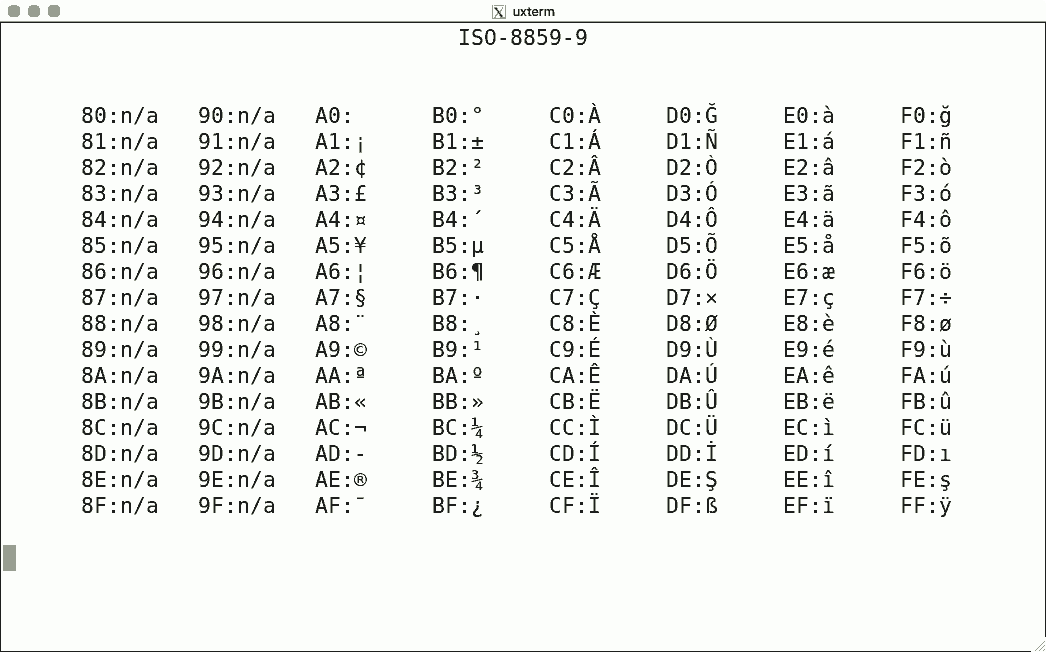
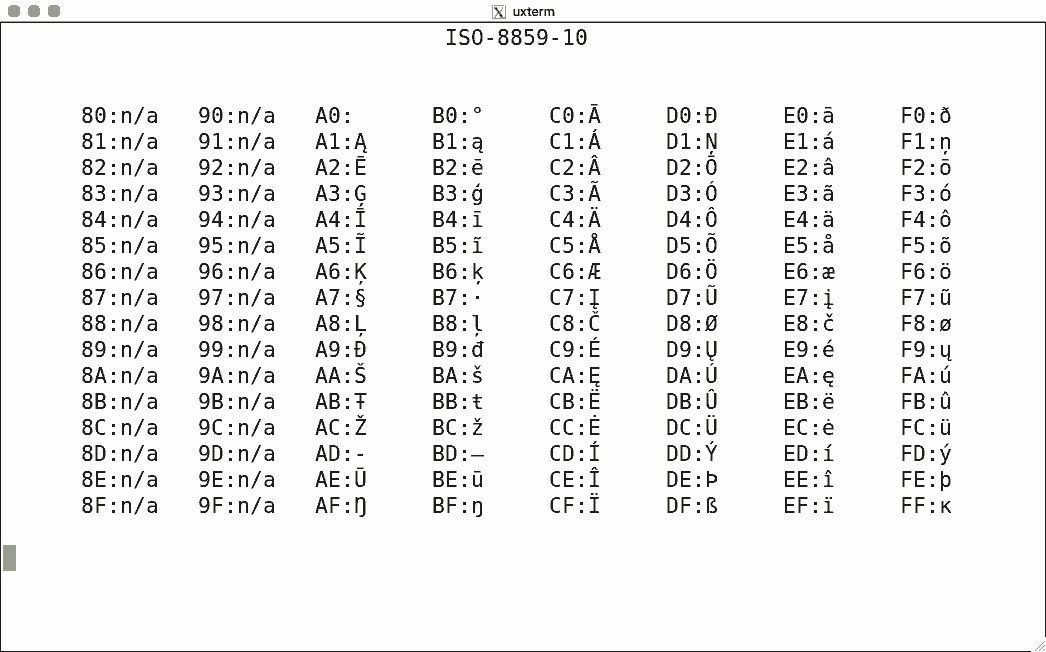
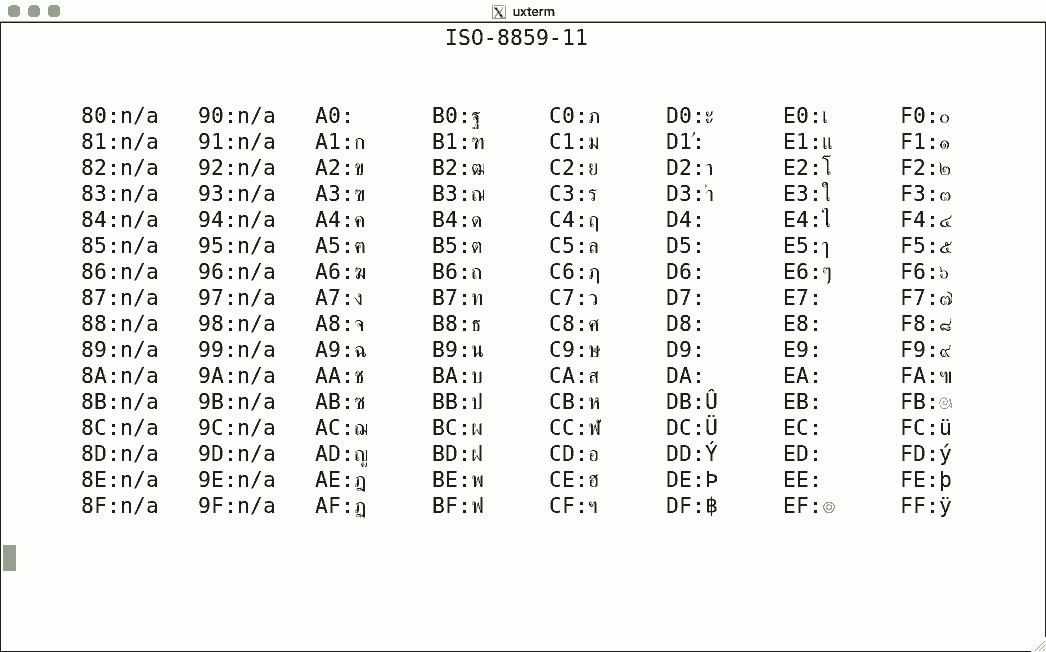
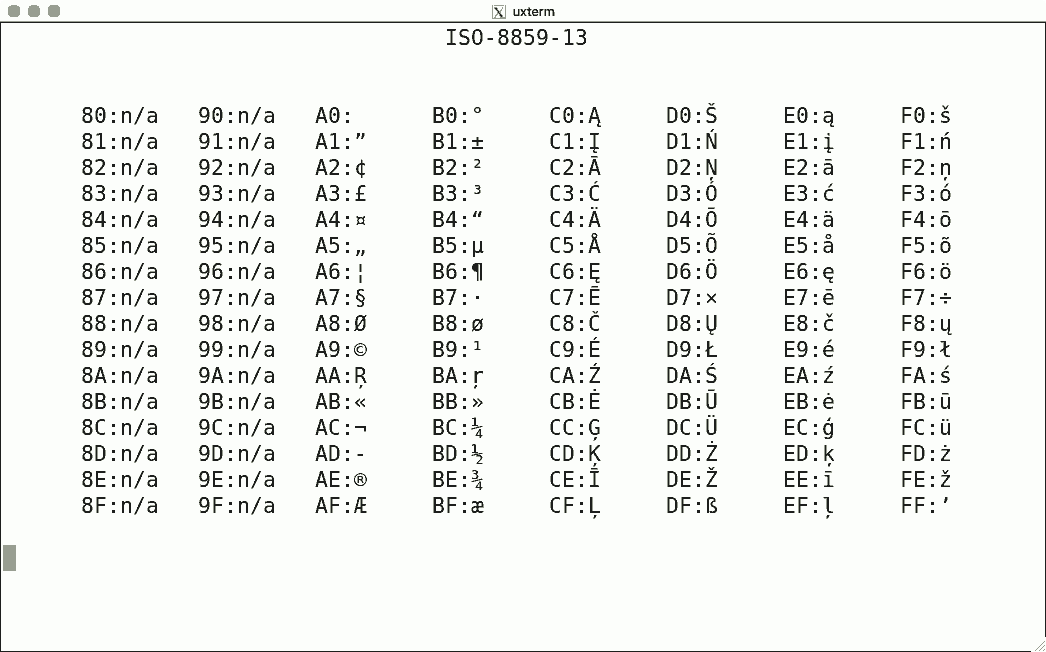
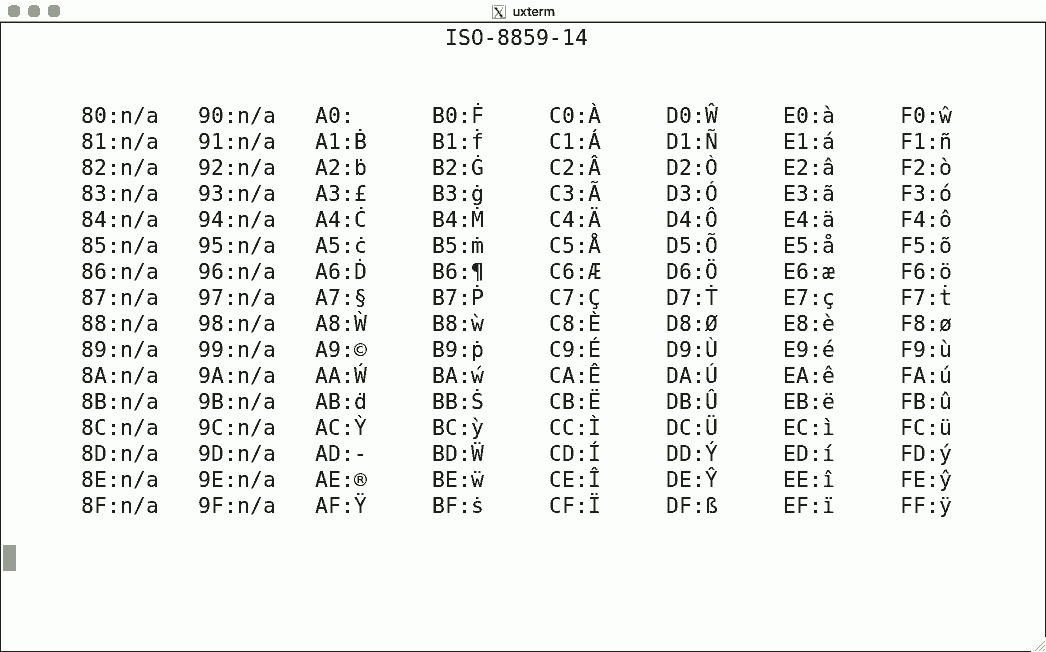
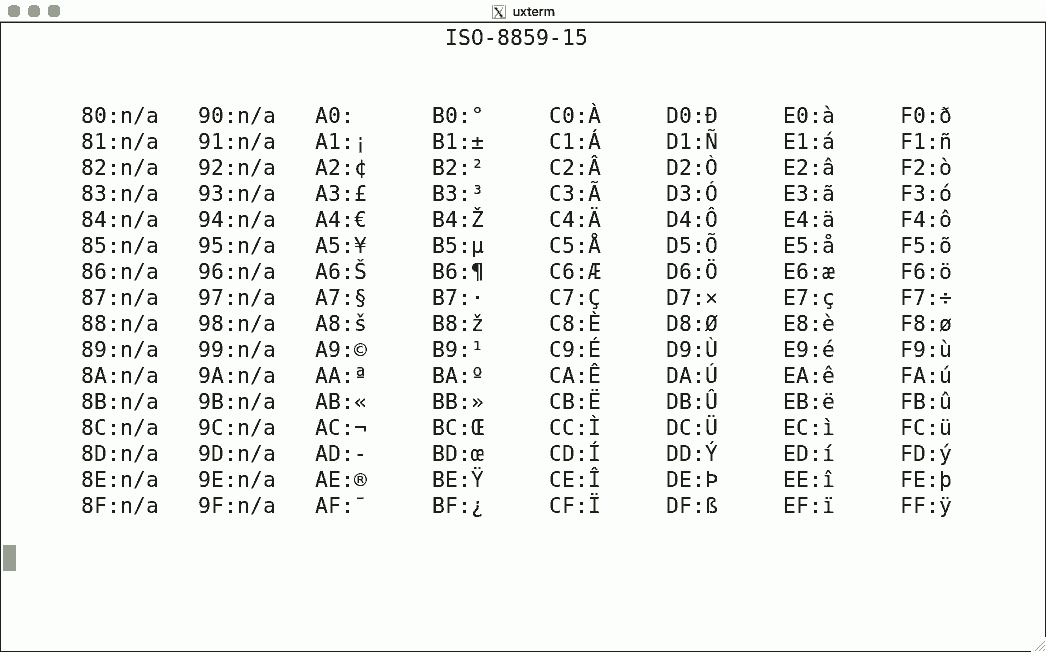
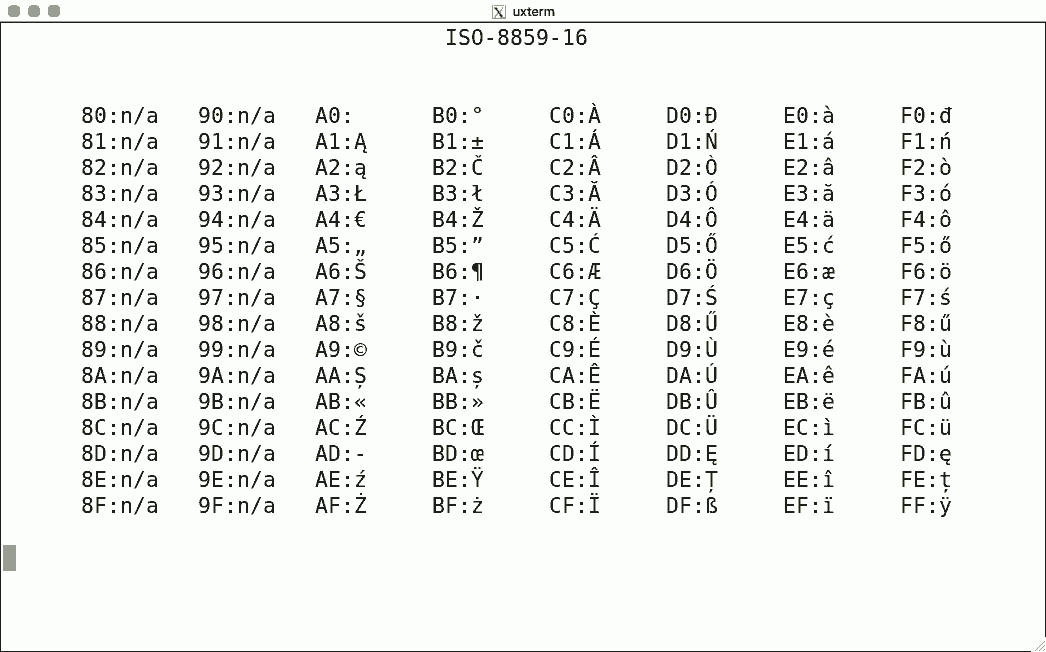
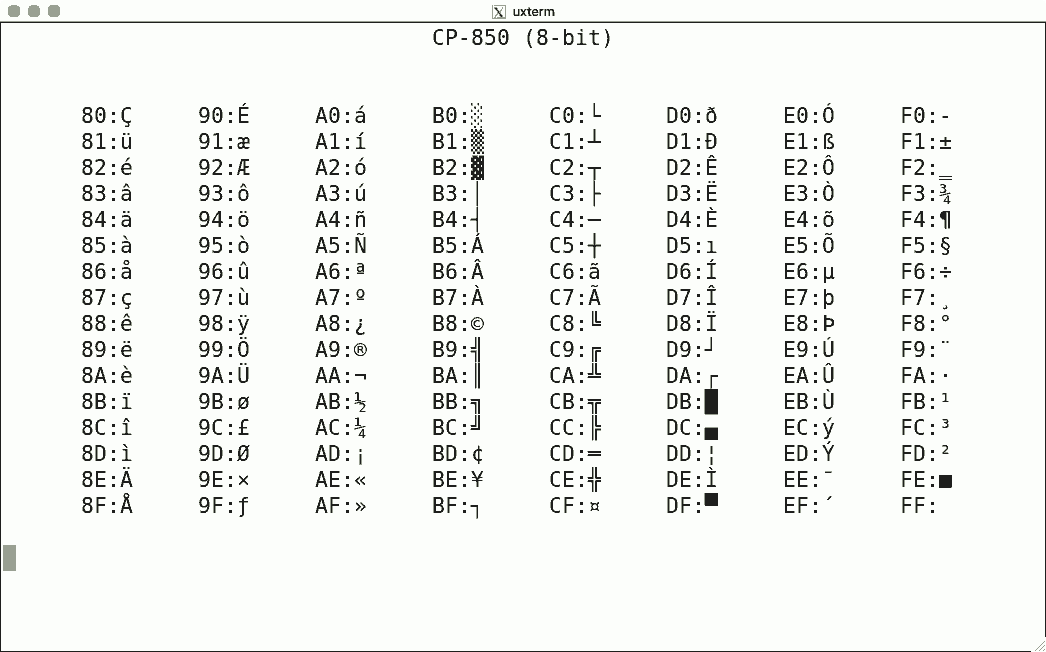
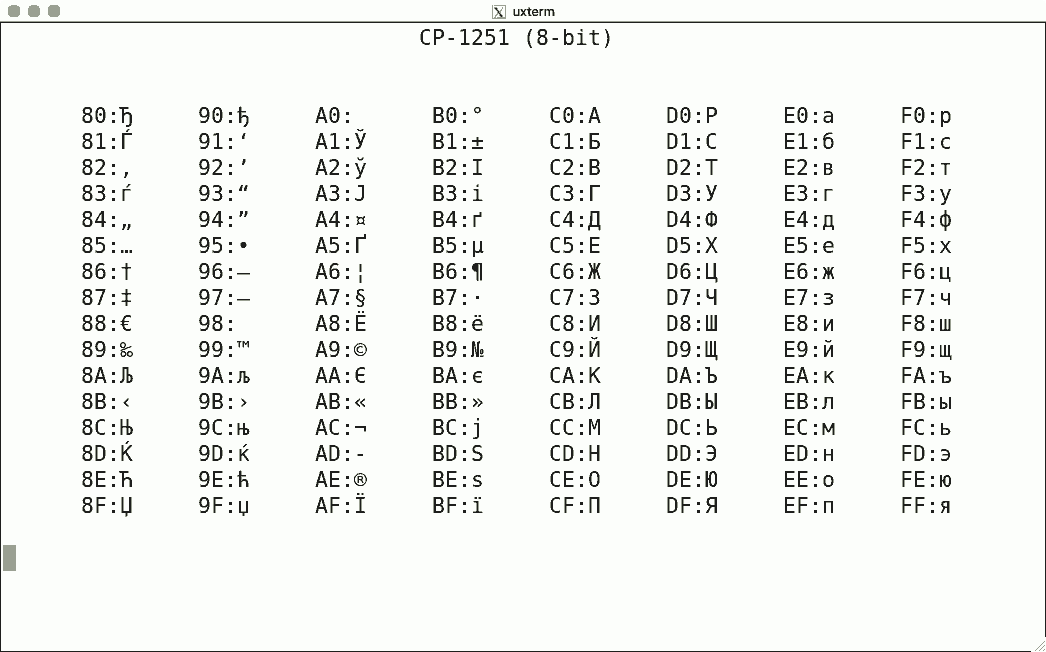
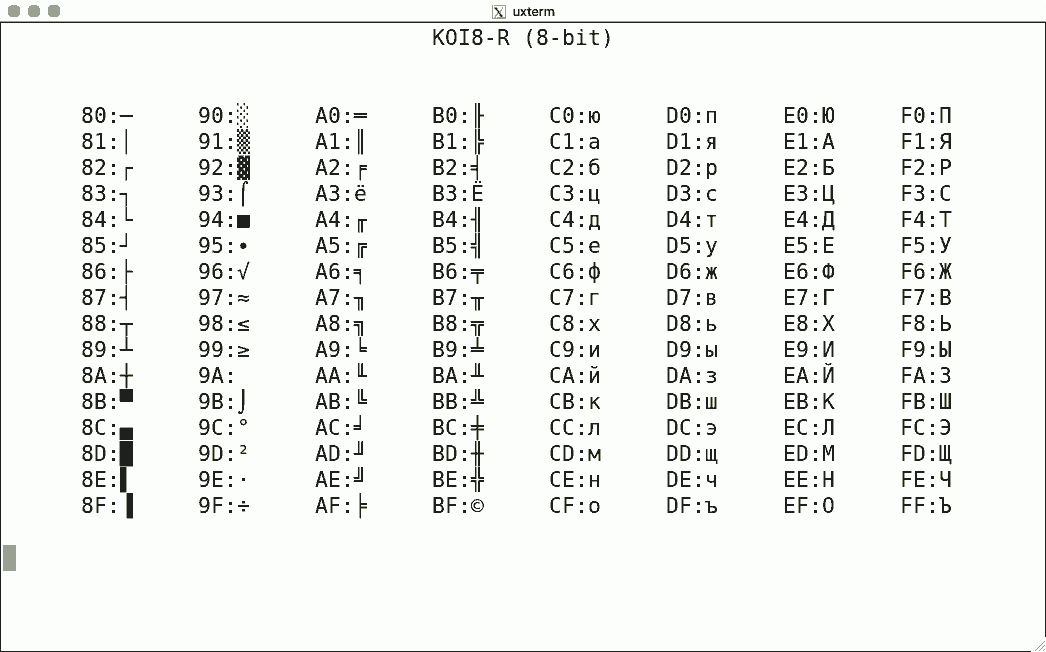
DEC's terminals are the best-known because of the VT100. The mainstream for character encoding is different: ISO-8859-x. Here are screenshots for the available encodings.
I used the same script for each, simply writing the binary code corresponding to the hexadecimal value to get the character rendered using luit. Note that 0x80-0x9f are "n/a" (not available) since the ISO encoding reserves these for C1 controls.
There is no ISO-8859-12
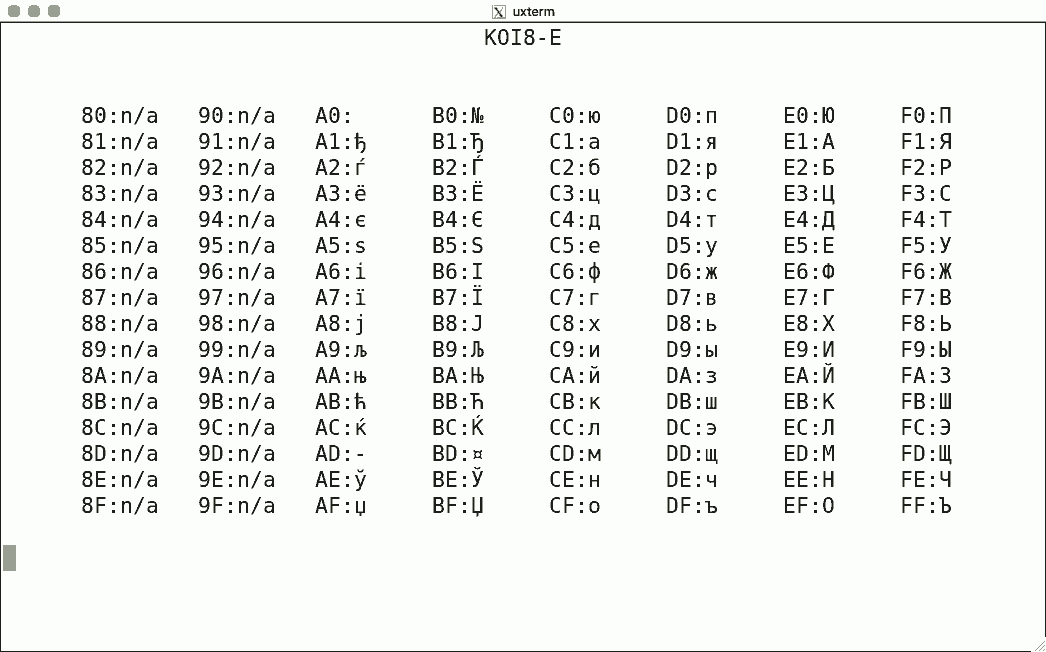
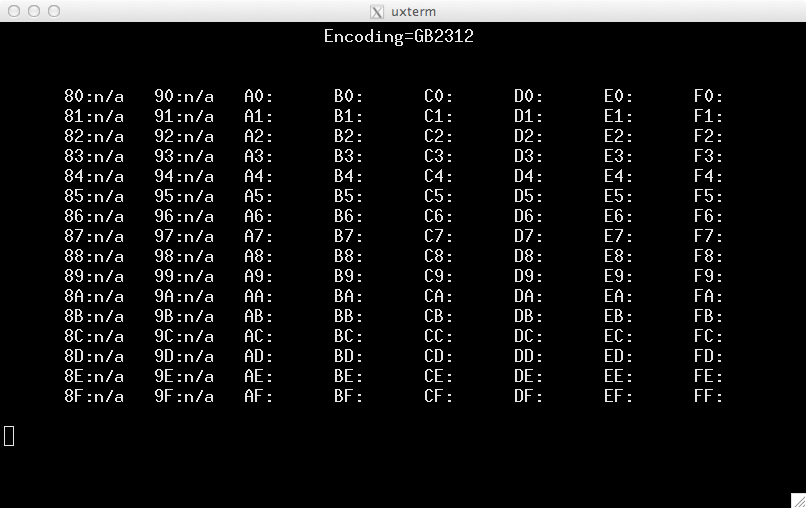
The ISO-8859-x character sets are a simple example of ISO-2022. There are others, such as the EUC (Extended Unix Code) character sets. The International Register of Coded Character Sets and IANA's Character Sets are good places to start reading.
EUC-JP is made up of multiple parts using the JIS X character sets. The first part (G0) is ASCII (and so there is no need for a screenshot). The other parts are mapped in luit to G1/G2/G3 and use two bytes per code, which does not work with my simple script:
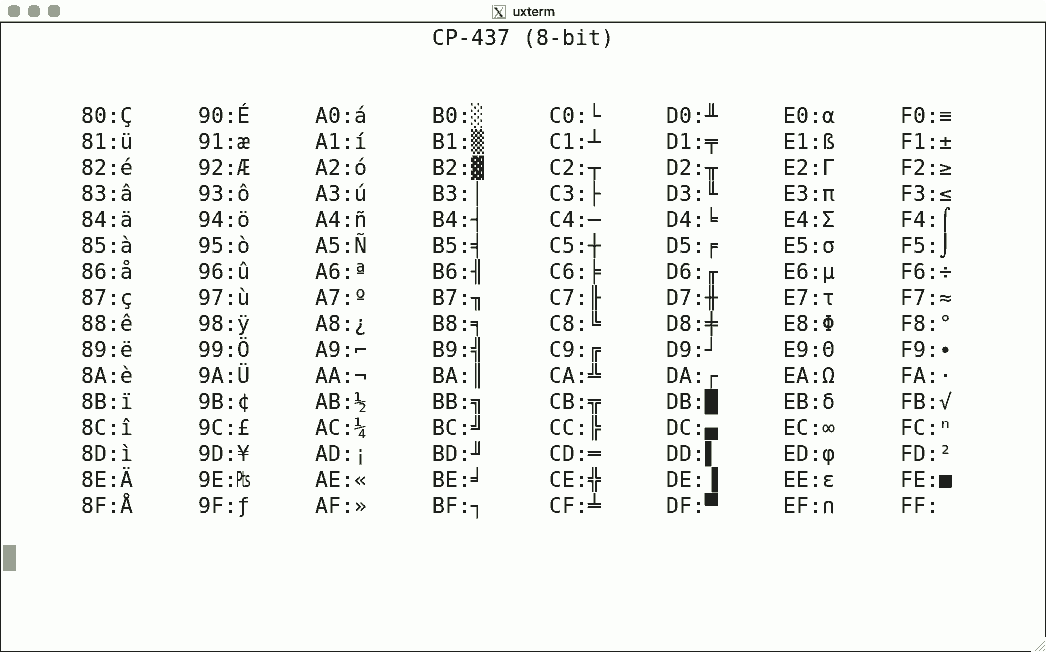
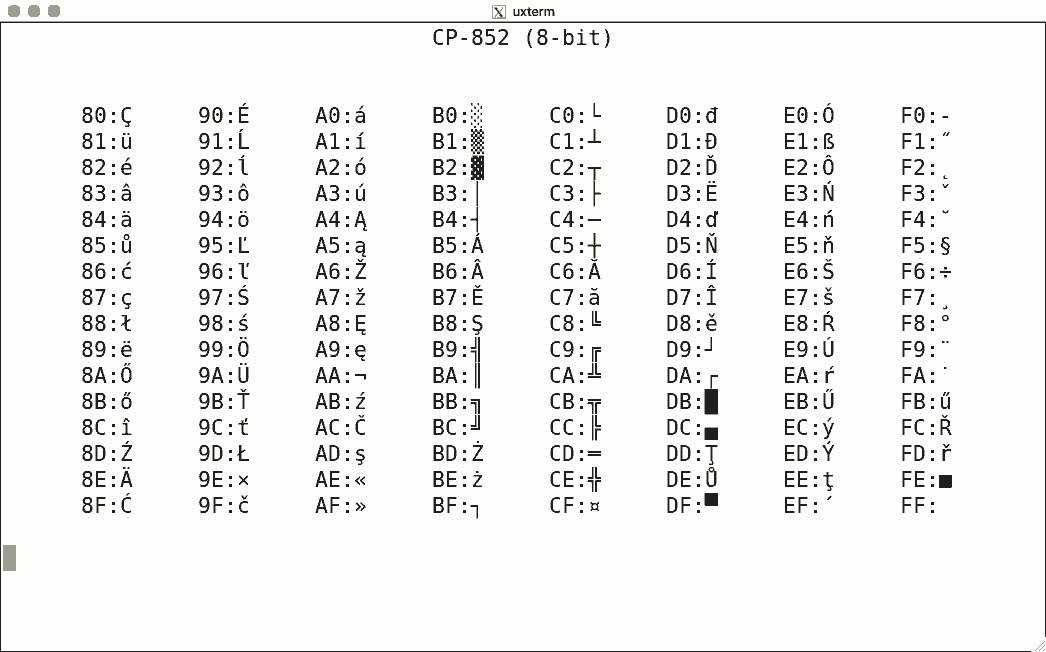
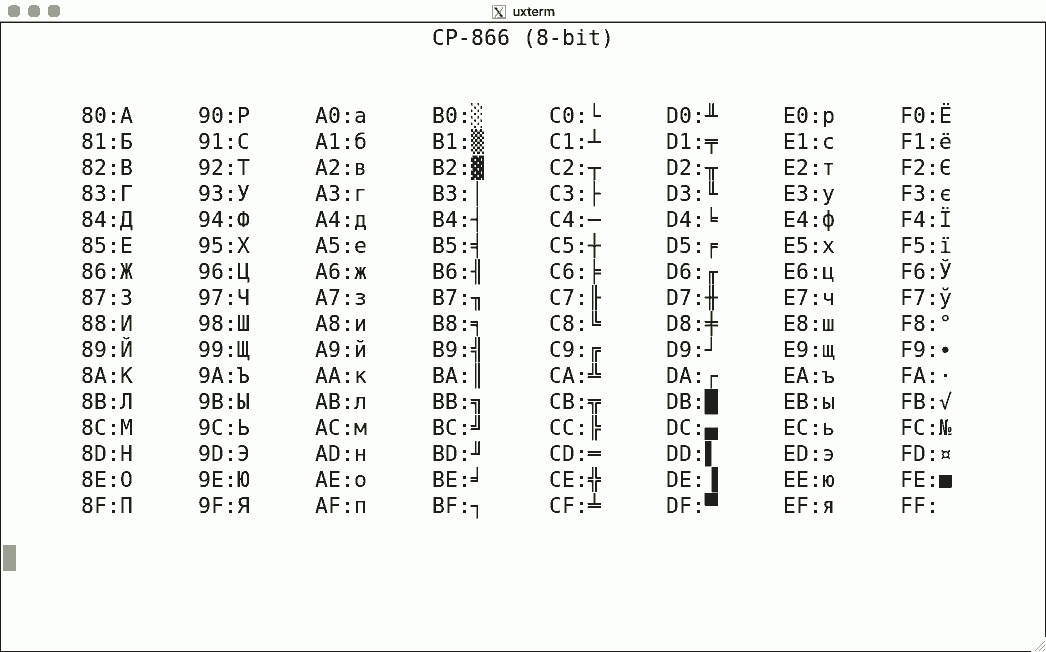
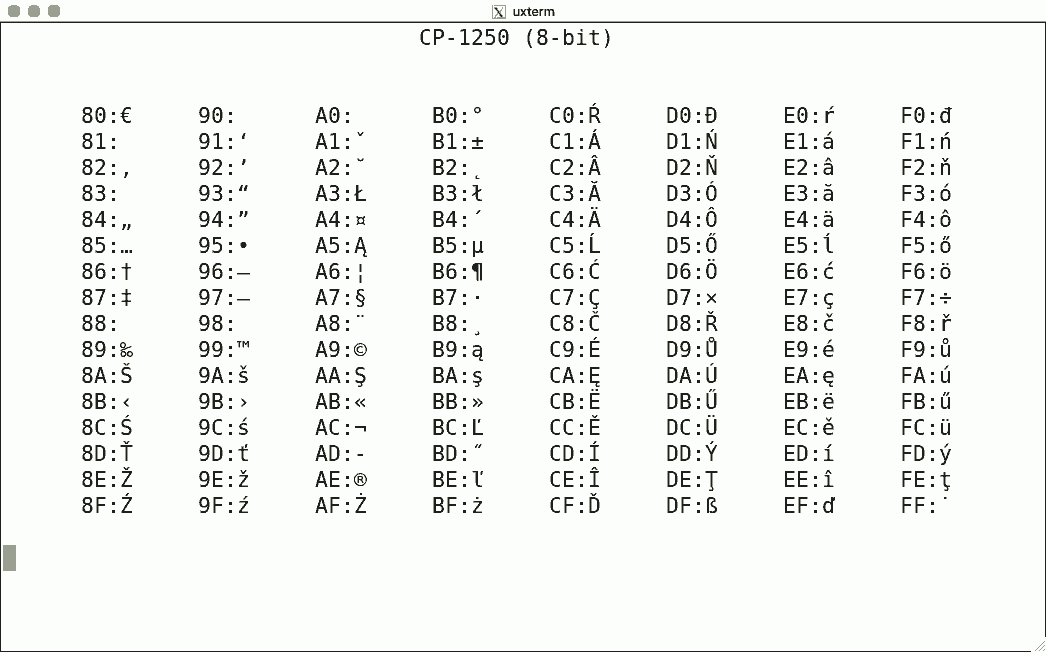
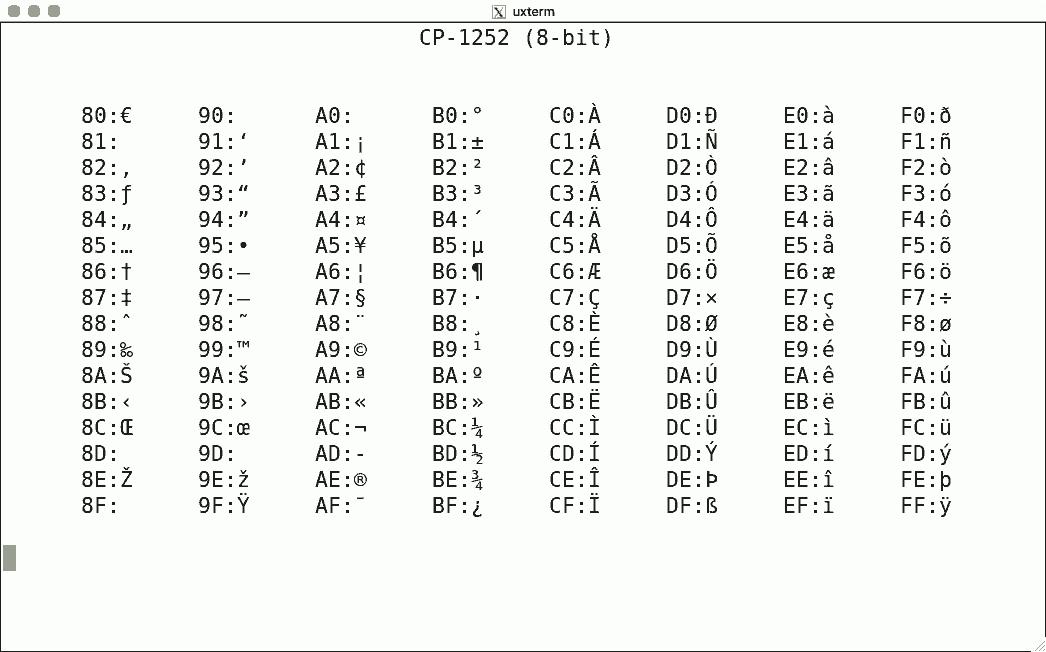
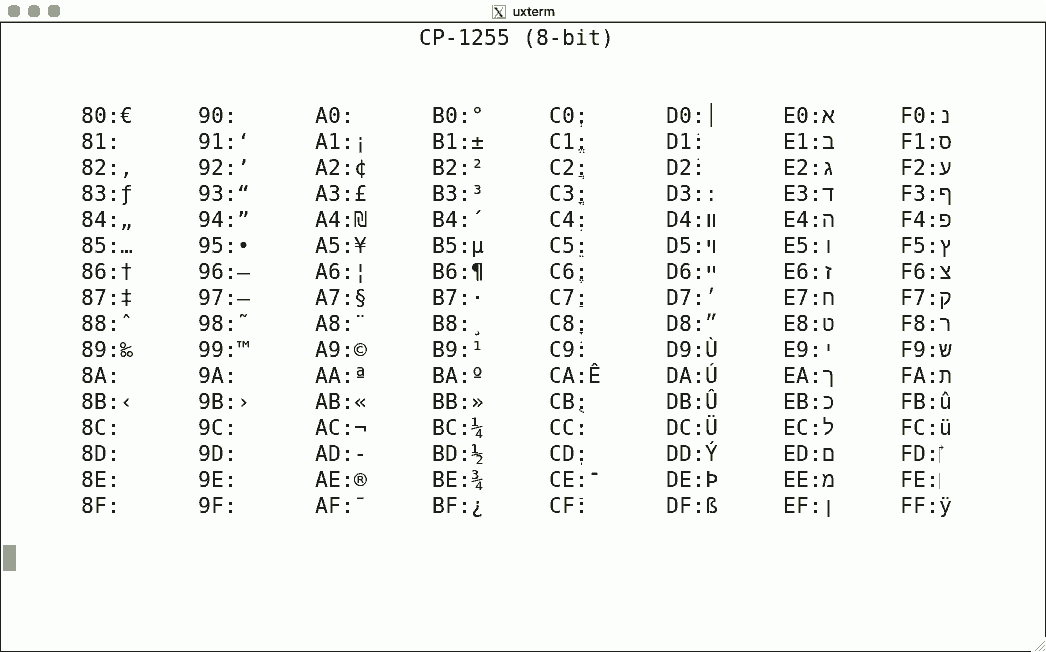
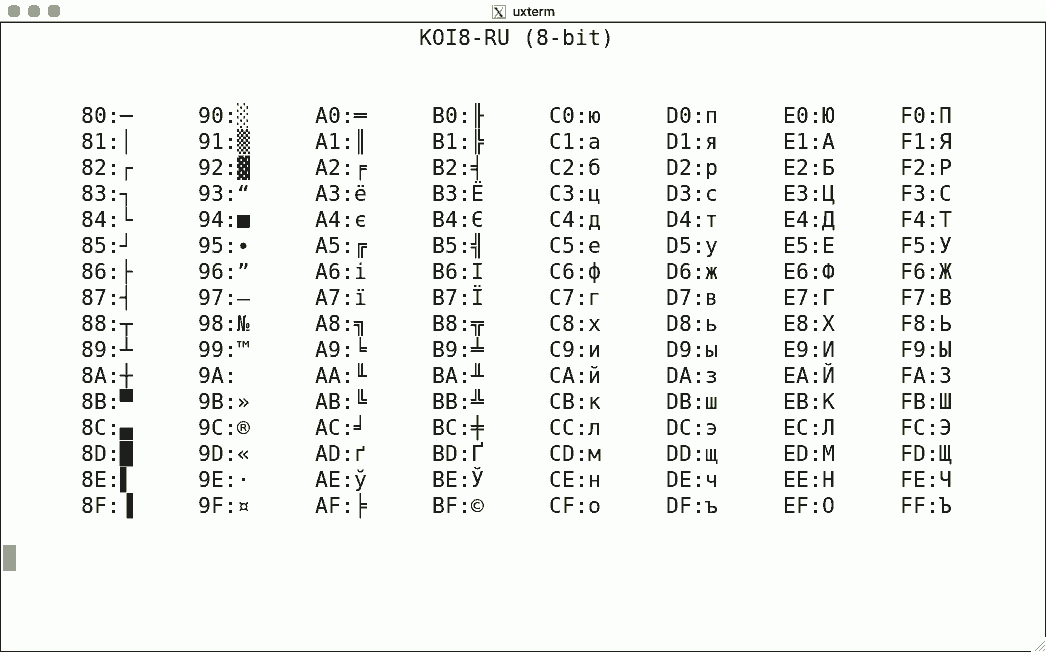
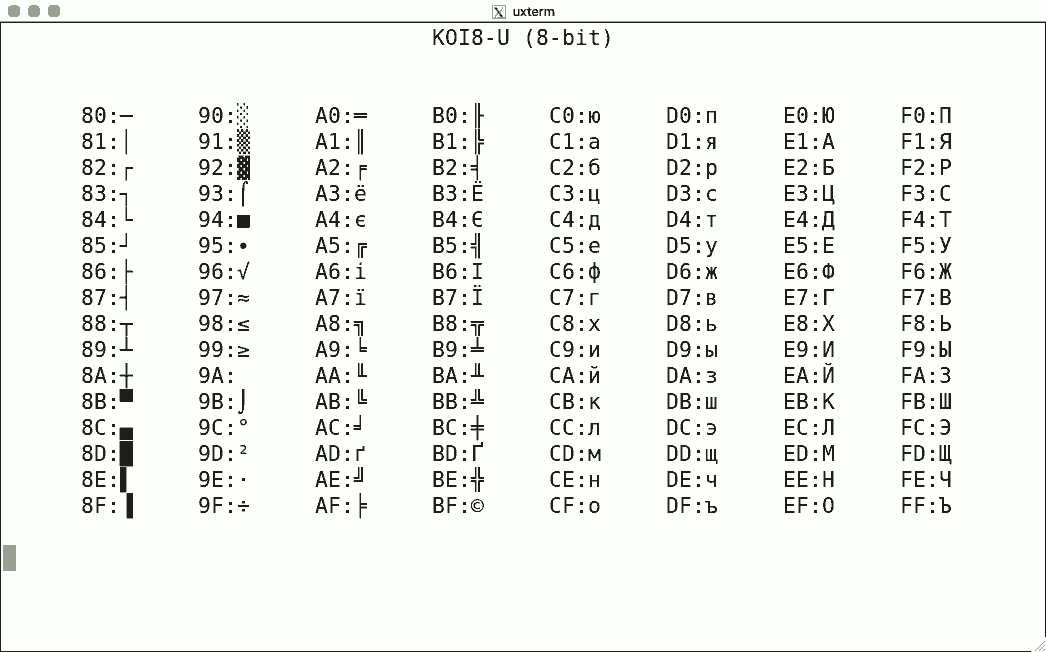
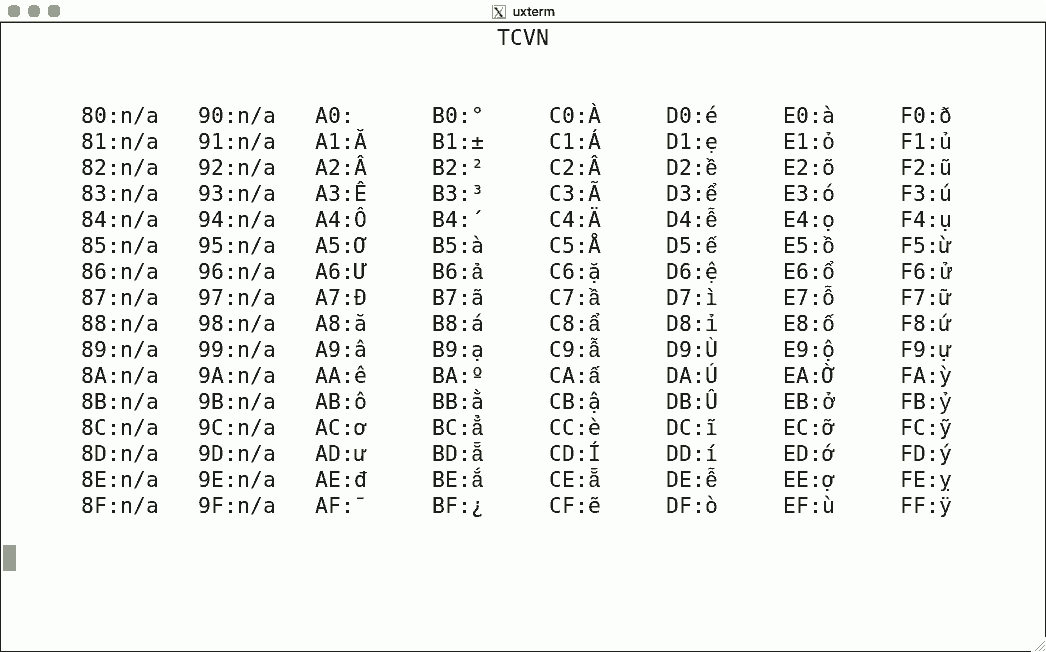
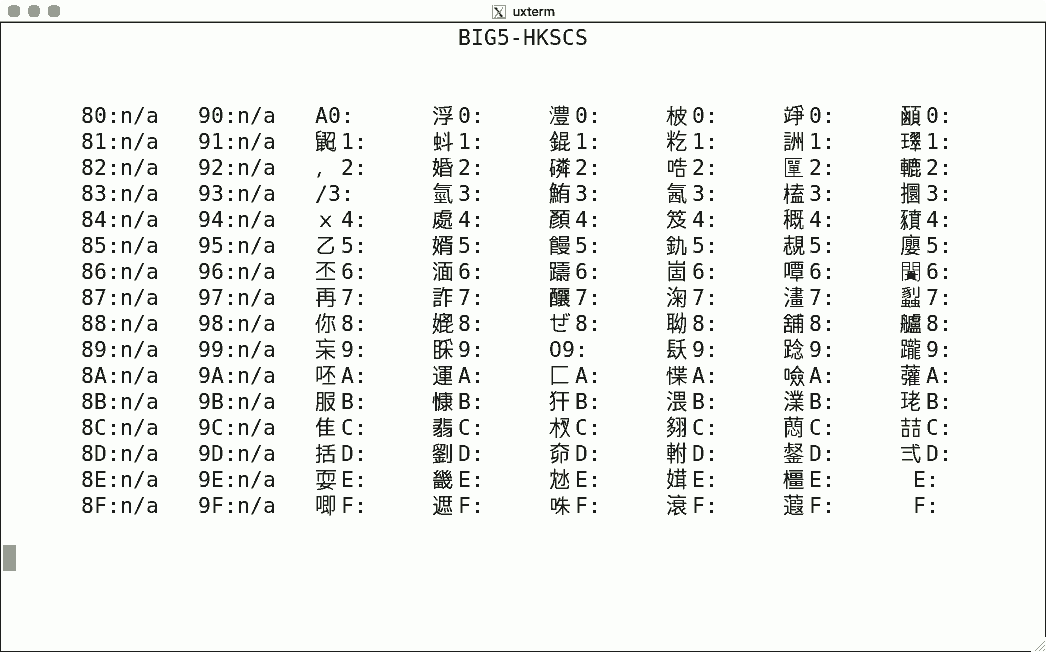
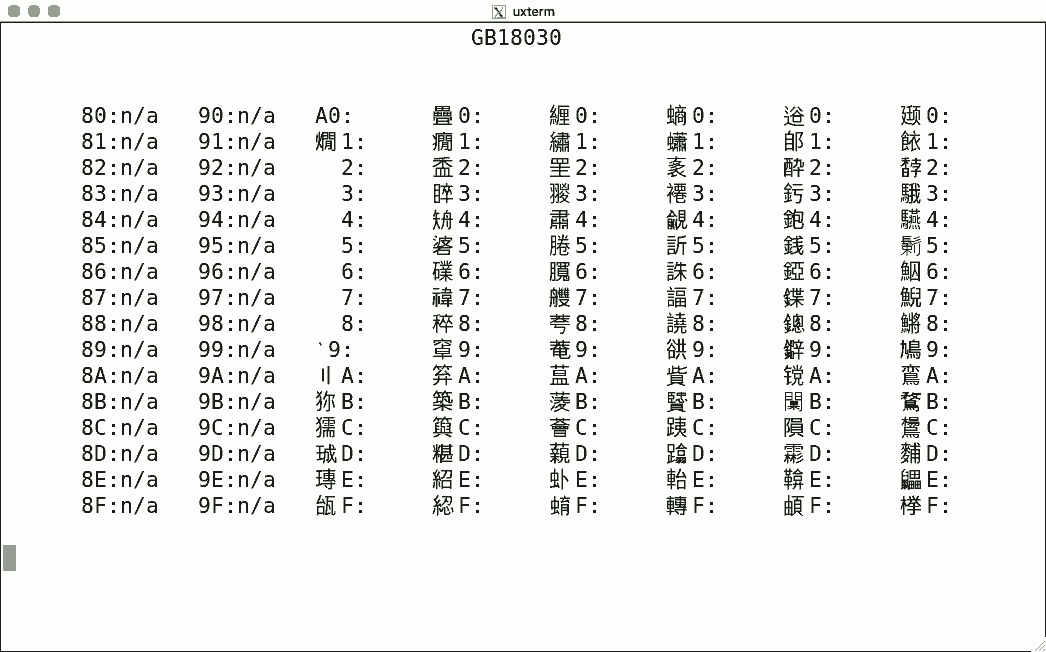
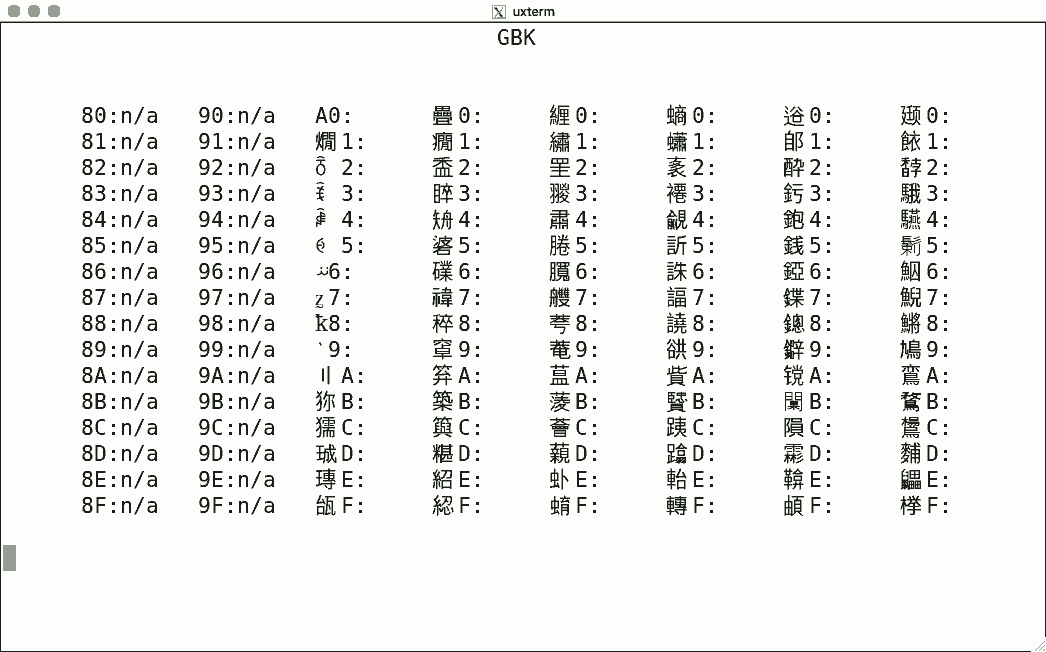
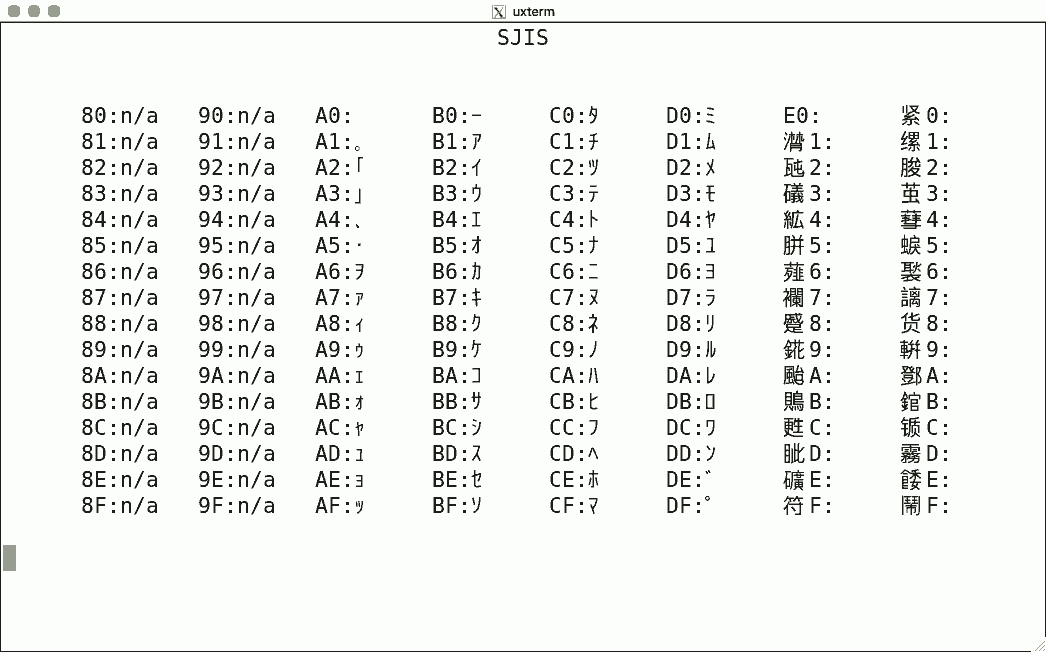
Luit also supports some non-ISO-2022 encodings. Here are some sample screenshots, again for codes 128-255.
This encoding uses two bytes, and the simple script shows nothing: