https://invisible-island.net/xterm/bad-utf8/
Copyright © 2020,2024 by Thomas E. Dickey
Markus Kuhn added rudimentary support for UTF-8 in the Linux console in 1996. Later, in April 1999, he began the support for UTF-8 in xterm (patch #97). Kuhn's initial implementation in the Linux console did rudimentary error checking, discarding unexpected input. Kuhn's changes for xterm were adapted from the Linux console source, but adding a comment:
/* Combine UTF-8 into Unicode */
/* Incomplete characters silently ignored,
* should probably be better represented by U+fffc
* (replacement character).
*/
Actually, the proper Unicode replacement character is U+FFFD, but that was a start. Shortly after, Kuhn provided a patch to use U+FFFD (in xterm patch #99).
Later that year, Kuhn created a demonstration file for valid input, and a test file for invalid input. He made minor improvements to both over the next few years, but no substantial revisions to account for changes to the Unicode conformance. The Internet Archive has a succession of versions of UTF-8-test.txt from Kuhn's website, but it has changed only a half-dozen times. The Internet Archive lacks the first two versions; here is a complete set:
XTerm (barring the occasional bug report) works with that file. XTerm also works with the demonstration file UTF-8-demo.txt, but this page is about the former, the test-file.
Others created similar demonstrations, e.g., Frank da Cruz' UTF-8 Sampler at Columbia as part of the Kermit project. Originally written to promote Kermit 95, da Cruz refocused it in 2011, noting
This, however, is a Web page, which started out as a kind of stress test for UTF-8 support in Web browsers, which was spotty when this page was first created but which has become standard in all modern browsers.
But developing a test suite for Unicode has been neglected. While the Unicode documentation takes about a hundred pages to describe how one might develop tests for conformance, it does not provide a reference implementation. As a result, developers have been presented with the opportunity of interpreting the (always incomplete) documentation. These provide interesting reading:
DRAFT - L2/02-149 Unicode Compliance Testing (2001)
In a section discussing ISO-5589:
If the converter distinguishes between illegal (source) values and unassigned values (in the target set), verify that the appropriate responses are generated:
- unassigned: U+0212, U+FFFD, U+10FFFD
- illegal: U+FFFF, U+10FFFF
That looks promising, until one reads it closely and realizes that the converter is only asked to recognize those invalid codes, not do anything in particular with them.
UNICODE CONFORMANCE MODEL (2008)
Section 2.5.1 says
A conformance test for the Unicode Standard is a list of data certified by the Unicode Technical Committee [UTC] to be "correct" with regard to some particular requirement for conformance to the standard.
and
A conformance verification test for the Unicode Standard is a test, usually designed and implemented by a third party not associated with the Unicode Consortium or the UTC, intended to test a product which claims conformance to one or more aspects of the Unicode Standard, for actual conformance to the standard.
That is, the emphasis is on handling correct data. How to handle errors is left to the implementors. That “usually” tells us that the Unicode organization is not going to develop a reference implementation.
Providing correct data (and mostly complete procedures) is good for demonstration purposes. Applications have to handle error conditions consistently.
Kuhn's test file is simple enough. One tests the terminal by
sending the test-file to the terminal, making it display the
result. One gauges the success of the test by checking that a
vertical bar “|” is in column 79.
Because it contains ill-formed UTF-8, some of the expected
display will be the replacement character. The position of the
vertical bar takes that into account.
The test file has a few problems:
Two of the test-file lines lack a vertical bar (sections 2.1.1 and 2.2.1). Kuhn left those out on the first revision of the file, in November 1999.
Kuhn apparently assumed that U+0080 would display like a space. Terminals do not do that; it is used for padding. Unicode agrees with that description, saying it is a control character.
Section 5 of the test-file uses codes that Unicode says explicitly are not characters. Kuhn apparently assumed those would display as a double-cell (aka fullwidth) character.
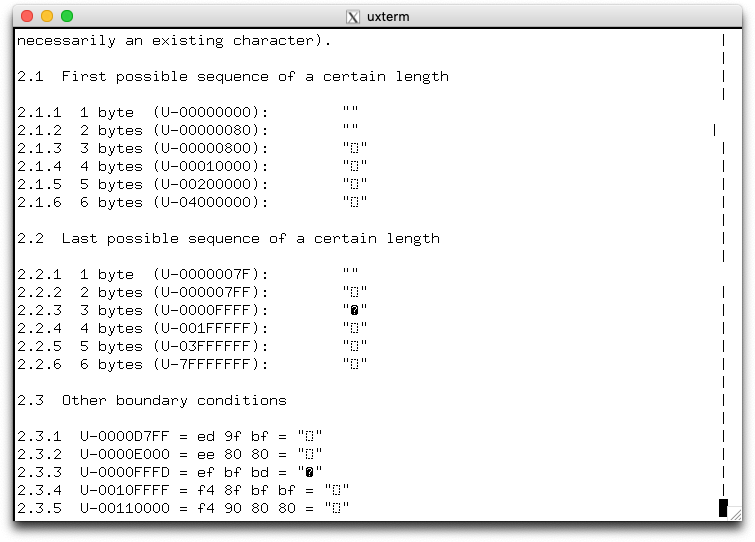
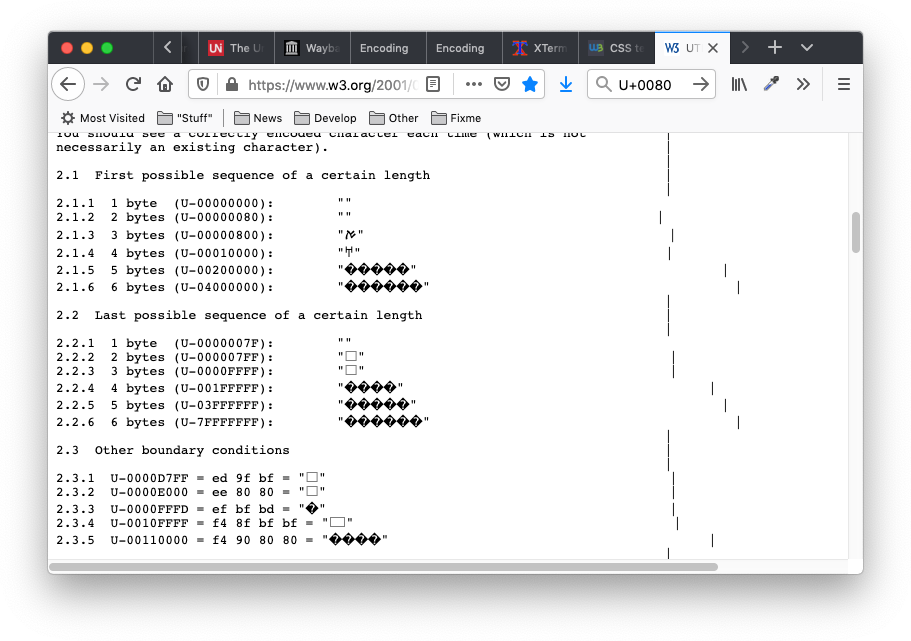
The test-file was intended for terminals, but after all, this is Unicode which is supposed to work everywhere—even with a web browser. Someone attempted to transform Kuhn's test file into a webpage, which can be seen on W3C's website. It looks different from xterm:
| xterm | Firefox |
|---|---|
|
|
|
On the Firefox side, the vertical bars do not line up. There are two reasons for this:
Firefox (and most web browsers) displays each byte of the ill-formed UTF-8 as a replacement character.
Even if one adjusts the test-file to account for that, it is not possible to make the vertical bars line up because Firefox does not have the replacement character available in a monospace font.
It turns out that is not just Firefox. Apparently font designers do not consider the replacement character useful.
There are other differences of course. Web browsers have no concept of control characters (aside from whitespace), so they are guaranteed to do the wrong thing when told to handle a padding character.
On xterm's side, some of the characters for which Firefox displays a replacement character are shown as empty boxes. For a while (from patch #233 to patch #334), xterm would have shown a replacement character, but the current scheme avoids doing that for characters which appear to be valid but missing.
Comparing the results in a web browser was an issue to explore because Dan Gohman suggested changes to xterm's error handling would have it imitate Firefox (or equivalently, act like a terminal whose developers imitate Firefox). That was motivated by a comment in the Unicode chapter 3 on conformance:
which overlooked the following (quoting from Unicode 13):U+FFFD Substitution of Maximal Subparts
An increasing number of implementations are adopting the handling of ill-formed subse-quences as specified in the W3C standard for encoding to achieve consistent U+FFFD replacements. See:
The Unicode Standard does not require this practice for conformance. The following text describes this practice and gives detailed examples.
The reference to W3C deals with the way Firefox displays multiple replacement characters. W3C's recommendation for Unicode is moot with regard to terminals, and actually not everyone agreed that it was suitable for browsers. For example in this page
Henri Sivonen disputes that. At the top of the page, he notes that the Unicode and ICU organizations amended their wording to avoid the appearance that W3C's approach is recommended (or “best practice”).
Ignoring that conclusion, the suggested changes might be relevant in terms of browser-like features imitated in some other terminals. In that regard, it could be useful as a resource setting for people who must deal with scripts which rely upon this feature.
I decided to explore this by comparing the results from Kuhn's test-file with and without Gohman's changes.
Because those changes are incompatible with longstanding
practice (more than 20 years), I refactored Gohman's changes as a
new resource setting
utf8Weblike.
By making the choice a resource, it is possible to make a
test-script which exercises the terminal with/without the feature
and compare the results. My script (called bad-utf8)
uses the terminal's cursor movement and reporting controls to
determine where the vertical bar is, and produce a copy of Kuhn's
test-file which would give the expected results (by adding or
removing spaces before the vertical bar).
Because those controls are part of the common VT100 repertoire, that script can also run successfully on other terminals.
I used the script to collect information on these terminals:
utf8Weblike enabled)Twenty should be enough. There are other terminals, but they have not distributed packages (or they are duplicates).
For testing, I used these machines (aside from xterm, the package versions cited above were current on those):
Kuhn's test-file numbers each of the test cases. My script reports “0” for each terminal if the test matched exactly. Each line in the test-file which does not match exactly adds one in the report. Most test cases have only one line of data; a few (e.g., 3.1.9, 5.3.3 and 5.3.4) have more than one.
Linux console, xterm (i.e., patch #358) and PuTTY were the only terminals which matched Kuhn's test-file closely (5-6 differences out of 98 data lines).
The table is here.
The bad-utf8 script constructs a file which could
be sent to the corresponding terminal with the vertical bars
aligned. It does this by adding spaces.
Counting the number of spaces needed may give more insight to how closely related the terminals are for error handling. Reviewing the results, you may see that the relative ranking does not change appreciably.
The table is here.
I wrote another script, diff-utf8 to process the
data collected with bad-utf8.
Beyond seeing how closely a given terminal matches the assumptions in Kuhn's test file, one might want to know if there are groups of terminals which give similar results. It turns out that there are two groups (more than two terminals having close matches):
xterm.js, vte-0.60 and xterm
(with
utf8Weblike enabled) are identical.
Linux console, PuTTY, xterm (patch #358) are the same except for two problematic test cases (see Analysis):
2.1.2 2 bytes (U-00000080)
2.2.1 1 byte (U-0000007F)
XTerm (and any VT100-compatible terminal) should
treat the corresponding single-byte values as nonprinting.
The latter is a single byte, but the former becomes
0xC2, 0x80.
0x7F by moving
the cursor left one column (bad-utf8 added a
space to compensate).U+0080 by moving
the cursor right one column (bad-utf8 removed
a space to compensate).A few other terminals are close to one of those groups. Most are not close.
The table is here.
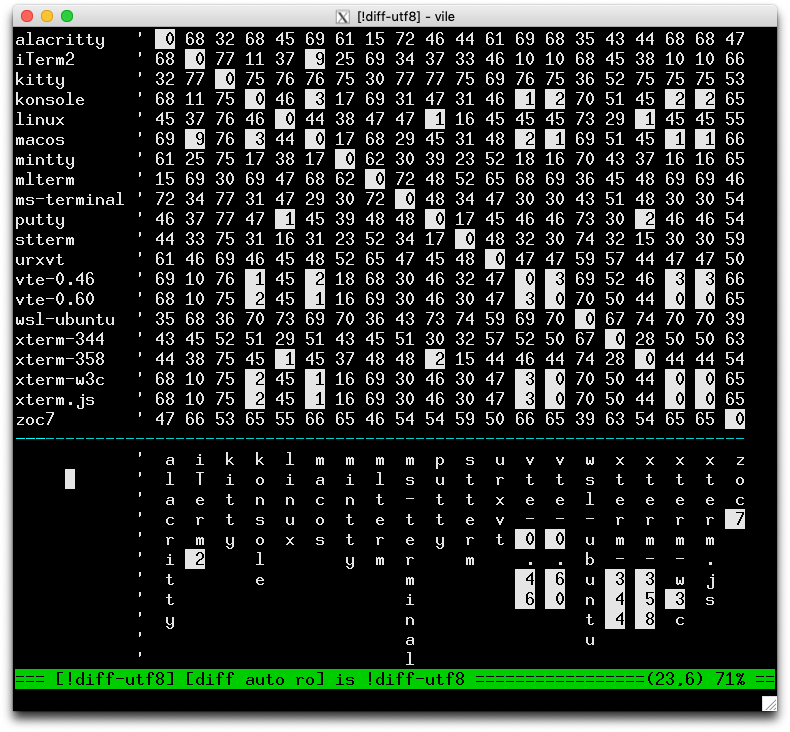
That table is large, and you may not pick out the pattern easily. In vile, I can see this using the editor's highlighting:
To explore this, I added a report to diff-utf8.
Initially, I had only tested vte-0.60, until noticing
that adding an earlier version would help explain the
relationships among these terminals:
** pairwise report .. level 0 xterm-w3c vs vte-0.60 xterm.js vs vte-0.60 xterm.js vs xterm-w3c .. level 1 putty vs linux (2.2.1) vte-0.46 vs konsole (2.1.2) vte-0.60 vs macos (2.1.2) xterm-358 vs linux (2.1.2) xterm-w3c vs macos (2.1.2) xterm.js vs macos (2.1.2) .. level 2 vte-0.46 vs macos (3.3.7, 3.4) vte-0.60 vs konsole (3.3.7, 3.4) xterm-358 vs putty (2.1.2, 2.2.1) xterm-w3c vs konsole (3.3.7, 3.4) xterm.js vs konsole (3.3.7, 3.4) .. level 3 macos vs konsole (2.1.2, 3.3.7, 3.4) vte-0.60 vs vte-0.46 (2.1.2, 3.3.7, 3.4) xterm-w3c vs vte-0.46 (2.1.2, 3.3.7, 3.4) xterm.js vs vte-0.46 (2.1.2, 3.3.7, 3.4) .. level 4 .. level 5 .. level 6 .. level 7 .. level 8 .. level 9 macos vs iTerm2 (2.2.1, 3.3.2, 3.3.3, 3.3.4, 3.3.5, 3.3.8, 3.3.9, 3.3.10, 3.4)
Recapitulating that in words:
utf8Weblike)
give the same result.In short,
The differences in xterm patch #344 versus patch #358
bear explanation. Patch #344 happens
to be the version provided in the current Debian 10 (stable), so
it was useful for comparison. Before Gohman's suggested changes,
he submitted a bug-report which required some scrutiny of Kuhn's
test-file, since it pointed out an additional case overlooked in
the fixes for patch #268. Since this was before writing
bad-utf8, with visual inspection alone, it was easy
to overlook an additional problem introduced in patch #328. Both
are fixed in patch #357, but
patch #358 was the most recently published version of
xterm when this page was created.
The history of other terminals' handling of ill-formed UTF-8 is just as complicated. Confining it to the story of how web-browser behavior came to be relevant to terminals, we have this:
Konsole's developers made the initial change in 2013:
commit 8dd47e34b9b96ac27a99cdcf10b8aec506882fc2
Author: Thiago Macieira <thiago.macieira@intel.com>
Date: Sun Oct 20 17:43:46 2013 +0100
Add a new UTF-8 decoder, similar to the encoder we've just added
Like before, this is taken from the existing QUrl code and is optimized for
ASCII handling (for the same reasons). And like previously, make
QString::fromUtf8 use a stateless version of the codec, which is faster.
There's a small change in behavior in the decoding: we insert a U+FFFD for
each byte that cannot be decoded properly. Previously, it would "eat" all bad
high-bit bytes and replace them all with one single U+FFFD. Either behavior is
allowed by the UTF-8 specifications, even though this new behavior will cause
misalignment in the Bradley Kuhn sample UTF-8 text.
Change-Id: Ib1b1f0b4291293bab345acaf376e00204ed87565
Reviewed-by: Olivier Goffart <ogoffart@woboq.com>
Reviewed-by: Thiago Macieira <thiago.macieira@intel.com>
commit d51130cc3a00df8147e2eb0799e06865c901c6e0
Author: Thiago Macieira <thiago.macieira@intel.com>
Date: Sat Oct 19 18:54:55 2013 -0400
Add a new UTF-8 encoder and use it from QString
This is a new and faster UTF-8 encoder, based on the code from QUrl. This code
specializes for ASCII, which is the most common case anyway, especially since
QString's "ascii" mode is actually UTF-8 now.
In addition, make QString::toUtf8 use a stateless encoder. Stateless means that
the function doesn't handle state between calls in the form of
QTextCodec::ConverterState. This allows it to be faster than otherwise.
The new code is in the form of a template so that it can be used from
QJsonDocument and QUrl, which have small modifications to how the
encoding is handled.
Change-Id: I305ee0fd8523cc4ec74c2678cb9ea88b75bac7ac
Reviewed-by: Thiago Macieira <thiago.macieira@intel.com>
There are a few problems with that:
Bradley Kuhn is a different person. Really, Bradley is unlikely to ever contribute to one of these projects.
Lacking other information, the reader is left with the understanding that the reason for this change was the convenience of copy/pasting from one Qt class into another. One alternative (that this was the only way to make it faster) is implausible, since returning multiple replacement characters would increase the amount of memory-allocation calls.
git://code.qt.io/qt/qt5.git, but did not find
it.Based on the commit-date, one assumes that this was in Qt 5.2, however the Git repository has no tag for ”5.2” (but ”5.3” is close enough).
VTE 0.46 was tagged 2016-08-15 (Debian 9's package says 0.46, but actually uses 0.45.90, since no "0.46" was tagged).
This version of VTE used GIConv (part of Glib), which in turn simply uses iconv.
Because it used iconv, error-handling was left to the discretion of the VTE (application). It provided a replacement character on each error, though iconv's behavior is unsatisfactory (i.e., iconv is not helpful when it comes to determining how many bytes to skip on ill-formed data).
Independently of this, the Unicode and W3C organizations came up with guidance in their respective areas:
Best Practices for Using U+FFFD. When using U+FFFD to replace ill-formed subsequences encountered during conversion, there are various logically possible approaches to associate U+FFFD with all or part of an ill-formed subsequence. To promote interoperability in the implementation of conversion processes, the Unicode Standard recommends a particular best practice. The following definitions simplify the discussion of this best practice:
concluding with
Neither of the code units <80> or <BF> in the sequence <63 80 BF 64> is the start of a potentially well-formed sequence; therefore each of them is separately replaced by U+FFFD. For a discussion of the generalization of this approach for conversion of other character sets to Unicode, see Section 5.22, Best Practice for U+FFFD Substitution.
That recommendation first appeared in Unicode 6's chapter 3 on conformance (February 2011).
However, the comments about “best practice” were removed in Unicode 11.0.0 (June 2018).
The W3C WHATWG page entitled Encoding Standard started in January 2013. It notes
The constraints in the utf-8 decoder above match “Best Practices for Using U+FFFD” from the Unicode standard. No other behavior is permitted per the Encoding Standard (other algorithms that achieve the same result are obviously fine, even encouraged).
Although Unicode withdrew the recommendation more than two years ago, to date (August 2020) that is not yet corrected in the WHATWG page.
The vte-0.60 changes date from 2018-09-02, with this:
commit b8b1aa4ed5ef12368c5c3f6d85ebf3e1d72f91a8
Author: Christian Persch <chpe@src.gnome.org>
Date: Mon Sep 3 16:10:51 2018 +0200
utf8: Make decoder conform to recommendation on replacement characters
With this change, the decoder conforms to the W3 Encoding TR and
the Unicode recommendation on inserting replacement characters
from §3.9 of the Unicode core spec.
https://gitlab.gnome.org/GNOME/vte/issues/30
That particular issue has been deleted, so it is not possible to determine who suggested the change, etc. Most of the change consisted of copying test-data from Henri Sivonen's encoding_rs project.
Sivonen provides a lengthy description in encoding_rs: a Web-Compatible Character Encoding Library in Rust.
At the time this change was applied, there was no longer a Unicode recommendation which was relevant. That was the previous year.
The developers for xterm.js made an improved Utf8ToUtf32 class in June 2019. Reading the source, there are a few differences in its boundary conditions versus the WHATWG code, but (see below) it gives an equivalent result using Sivonen's test-data.
Gohman brought the WHATWG page to my attention, as part of explaining why he thought it was a feature that xterm should do, and provided patches to implement it. While investigating this, I found that that it was no longer recommended by the Unicode organization.
Seeing that one of the pitfalls here was the absence of testing for the whole process, I added scripts to review differences between terminals.
In reviewing Gohman's changes, I noticed that he had removed the check which transformed surrogates into the replacement character. The WHATWG process for decoding UTF-8 does not mention surrogates, but it is possible to deduce that by a suitable test-case (lacking in that document). Henri Sivonen's code (with test-cases) was useful for that purpose.
The bad-utf8 script works by printing a line from
the test-file, finding where the cursor is after printing, and
computing an adjustment. It attempts to handle line-wrapping, but
in practice some of the terminals tested differ too much in their
handling of wrapping to make that work reliably. Running the
script on a terminal sized at least 90 columns wide gives good
results. I chose the Arch Linux console for testing because it
had been set up as a wide display.
Besides wrapping, one must be careful to not interrupt the terminal while it is processing the test-cases, because that can interfere with the cursor-position report.
The bad-utf8 script updates a CSV-file for each
completed test on a given terminal, while also writing a copy of
the adjusted test-file. There are two CSV-files, chosen according
to whether an option is used to tell it to report test successes
or the amount of adjustment needed. The adjusted test-files in
either case should be identical. I ran the bad-utf8
script more than once, ensuring that those files were in fact
identical (indicating that no data was lost or corrupted due to
timing or inadvertant interference with the cursor-position
reports).