http://invisible-island.net/vttest/
Copyright © 2013-2018,2020 by Thomas E. Dickey
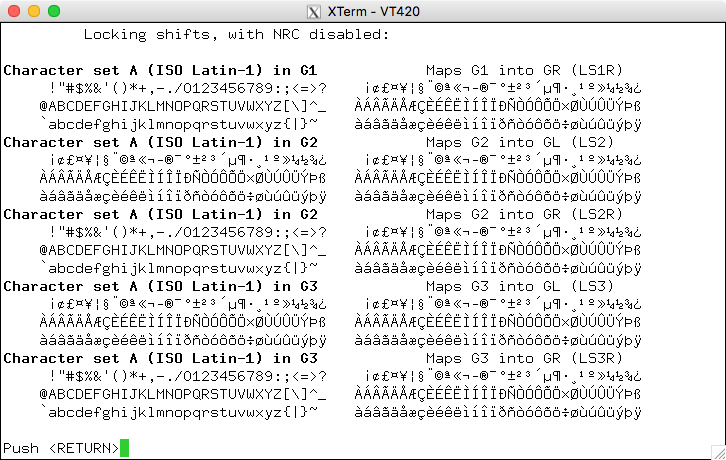
XTerm's default encoding is ISO-8859-1 (also known as Latin-1). Here is an example:
That is, an application written for the VT220 (or higher-level DEC models) would send one byte per character, expecting the result to look like that. ECMA-35 describes how to select different character sets.
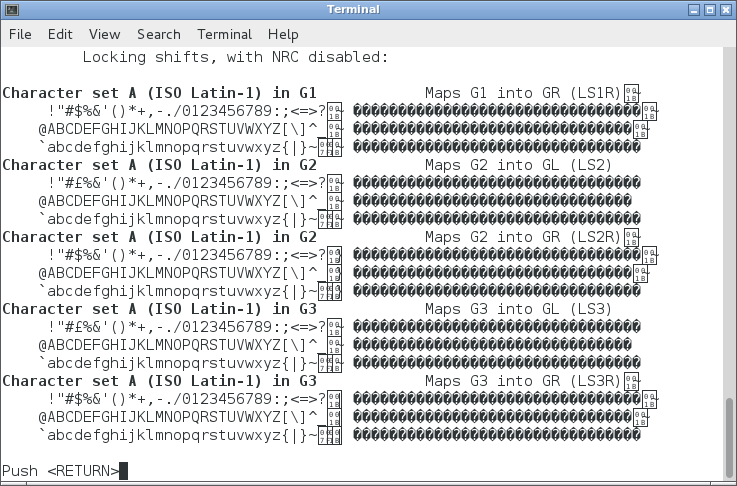
The result may change if the application sends those bytes to a terminal which uses UTF-8 encoding. If no translation is done, you might see something like this in older versions of xterm:
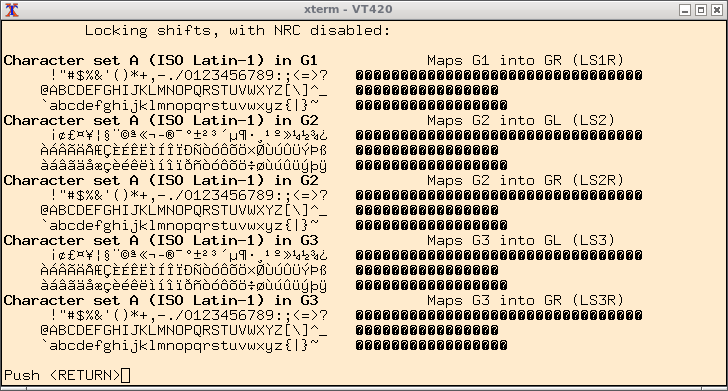
The reason is that the characters drawn on the right side of the picture use codes in the range 160-255, which have a different meaning if interpreted as UTF-8.
I extended the vt100Graphics
resource in 2018 to
support the VT320- and VT520-codepages. The result is
improved:
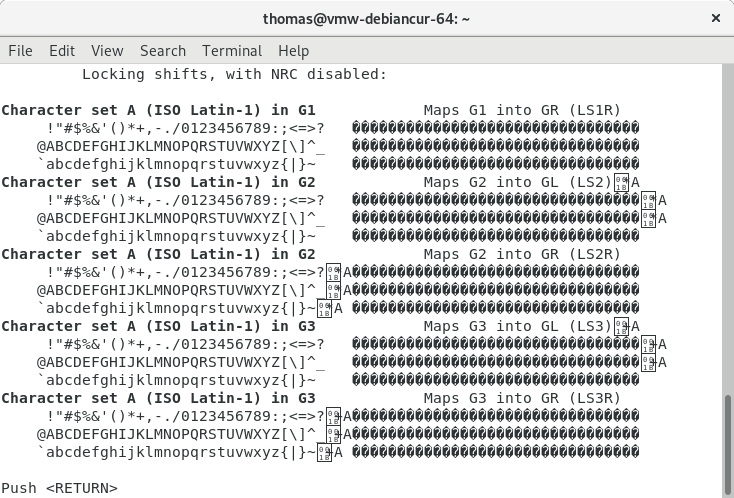
On the other hand, there is no good reason for this (VTE):
VTE's developer copied source-code from xterm to “implement” NRCS in 2002. It never worked well, and newer versions of VTE dropped all support for VT220-style NRCS in 2014, except for a small section of Latin-1 to imitate xterm (see bug report). Here is a screenshot showing the result:
As of 2018, however some package descriptions still claim
Run any application that is designed to run on VT102, VT220, and xterm
No part of that statement is true.
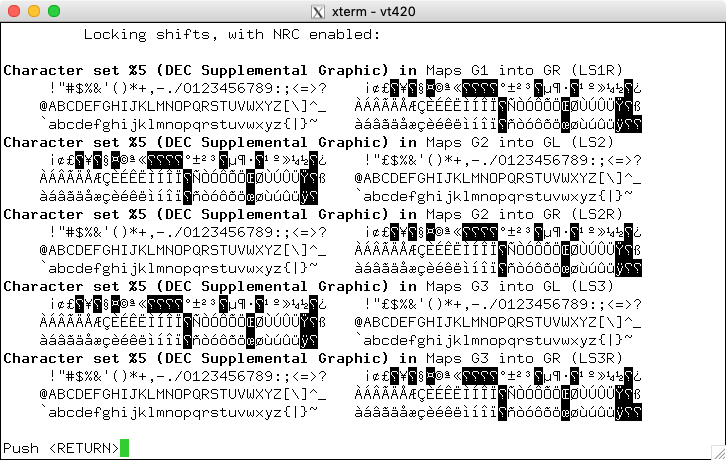
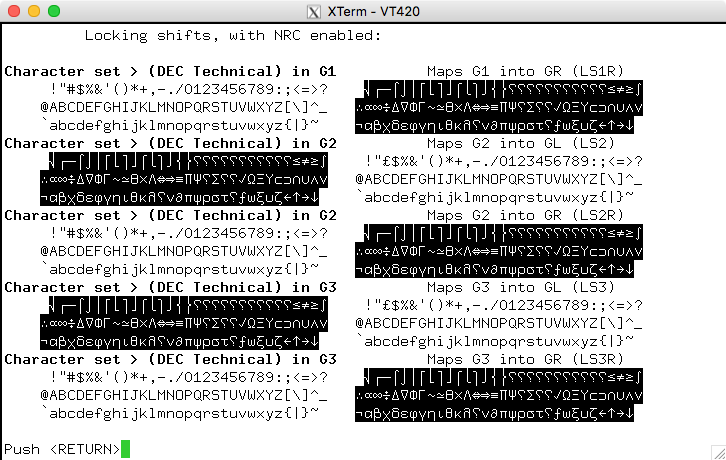
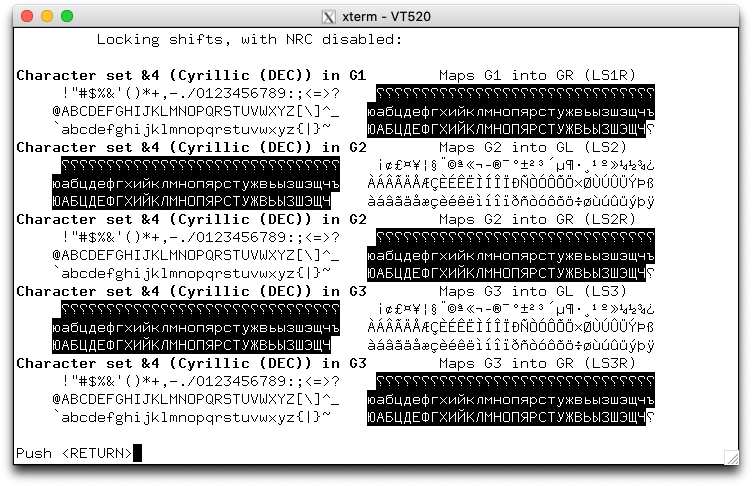
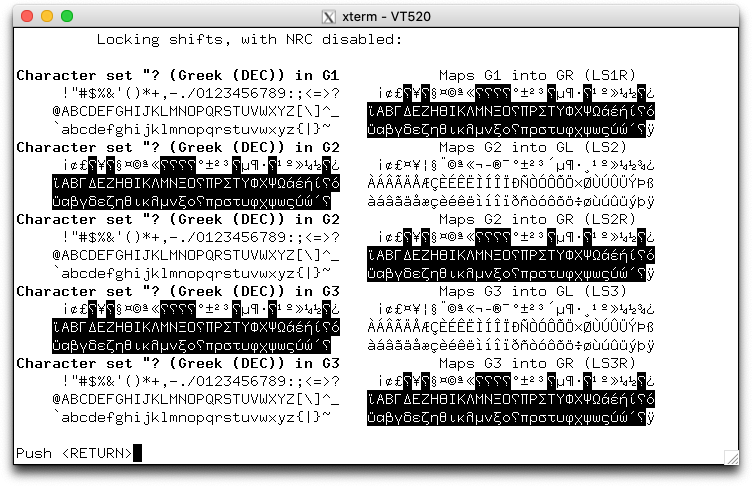
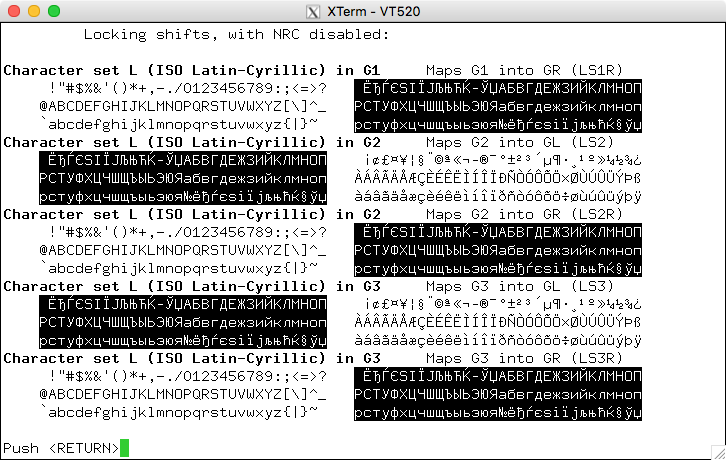
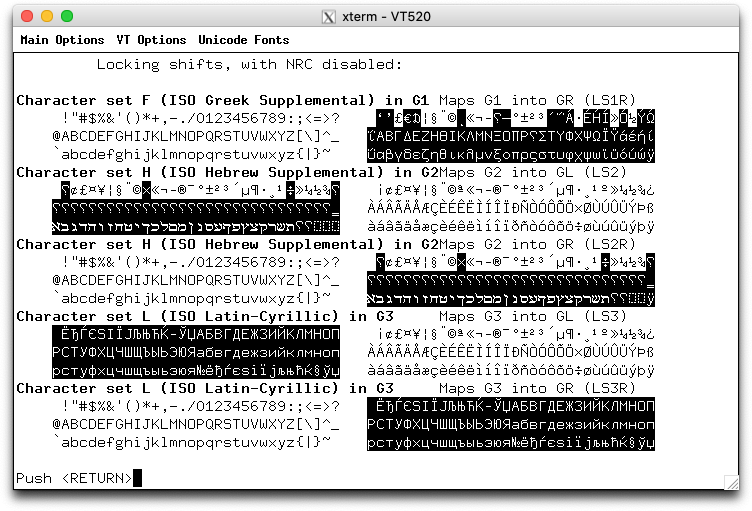
Some of DEC's character sets were provided as part of the National Character Replacement feature introduced with VT220. Others were successive versions of character sets which ultimately were standardized by ECMA and ISO in the early 1980s. Finally, some were useful graphics characters which were not standardized at the time.
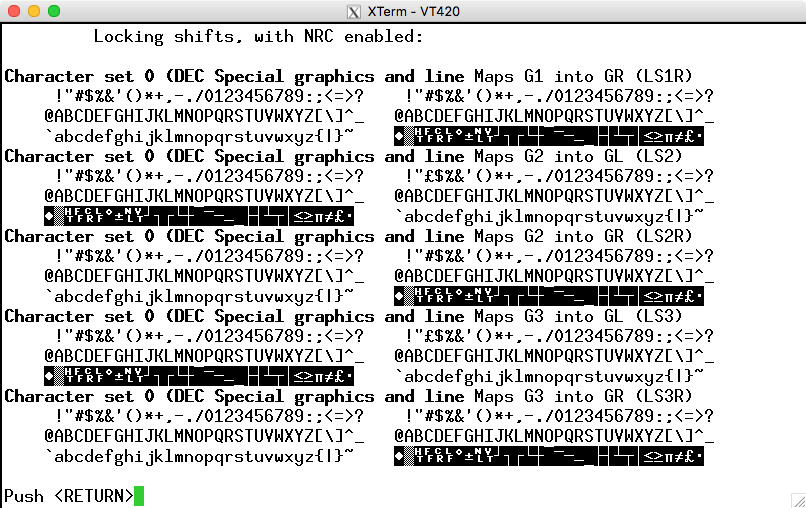
Treating the special graphics character set as an NRC, the highlighted characters show which are not in the ASCII character set.
Also known as the Multinational Character Set, this was introduced in the VT220 to support the National Replacement Character feature. The highlighted cells show which do not match ISO-8859-1:
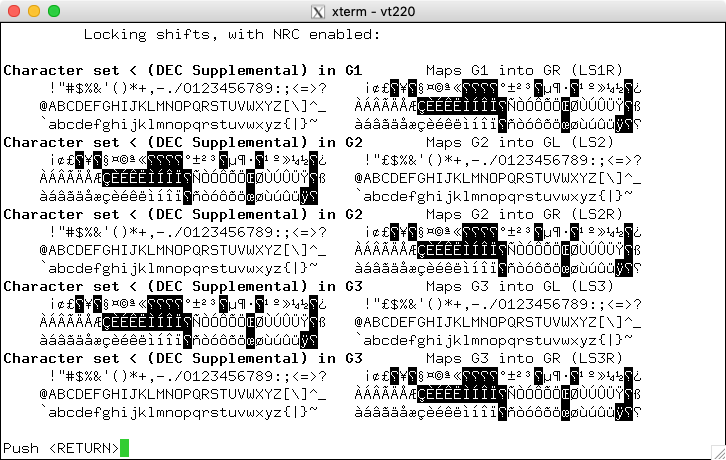
Also known as the Multinational Character Set, this was introduced in the VT320, e.g., as an interim step toward standardization of the Latin-1 character set. The highlighted cells show which do not match ISO-8859-1: